定义
如果在一个图中,删除某个节点连同与之关联的边,会导致整个图的连通分支数增加,那么这个节点叫做 割点(Articulation Point, Cut Vertex)
如下图:
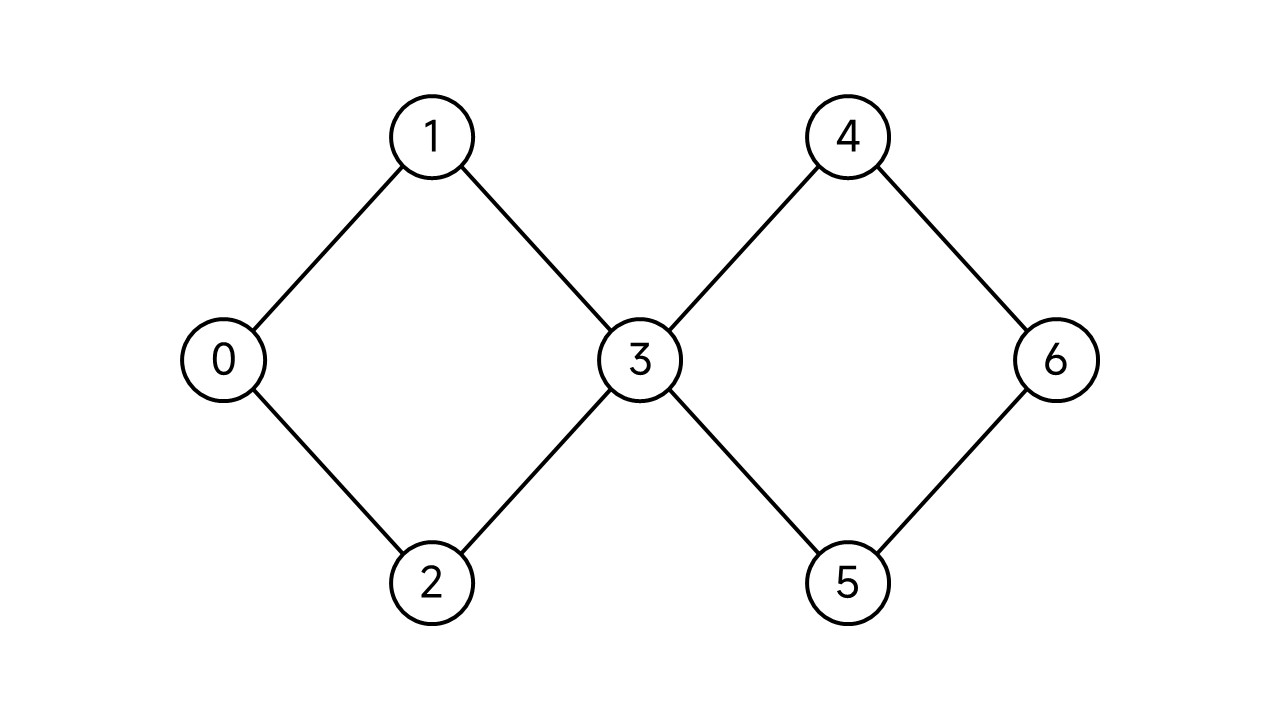
整个图的连通分支数为1,但是删除节点3后,整个图就“分裂”成了2个连通分支:
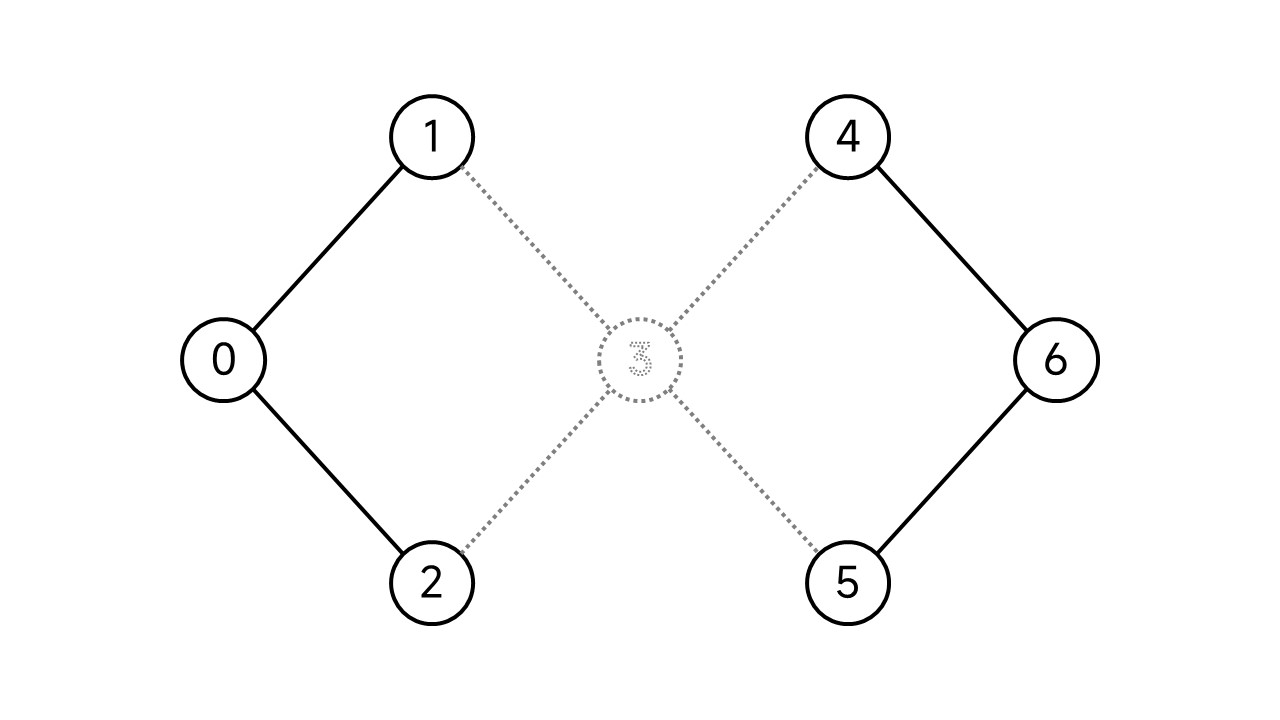
因此,节点3是整个图的割点。
方法
一个很容易想到的方法是,依次删除图中的每一个节点,看剩下部分的连通分支数增没增加。但是那样显然太浪费时间了!有没有一种办法,能够快速的找出整个图的割点呢?
Tarjan算法的核心思想:深度优先遍历(DFS)这张图,得到的DFS树(由遍历路径和节点构成的树)中,当某个节点u满足以下条件之一时,它就是割点:
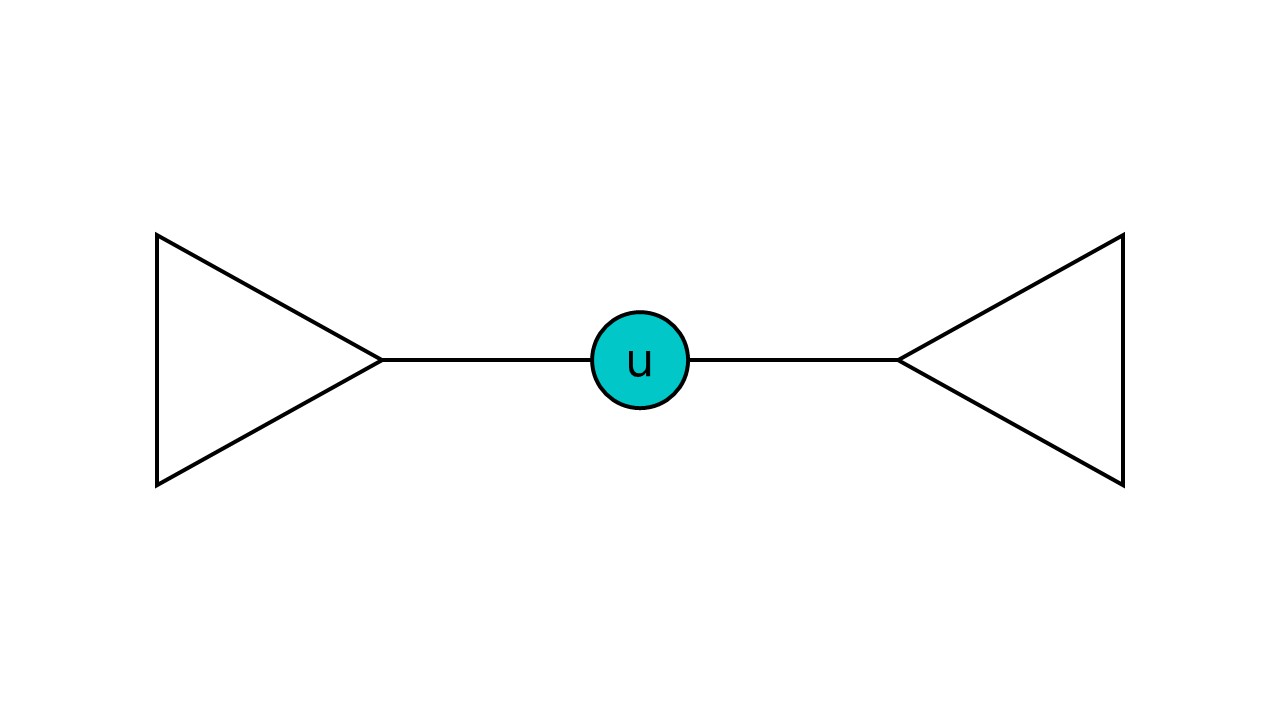
- u为DFS树的树根,且u有2棵及以上的子树,如图(三角形代表子树):
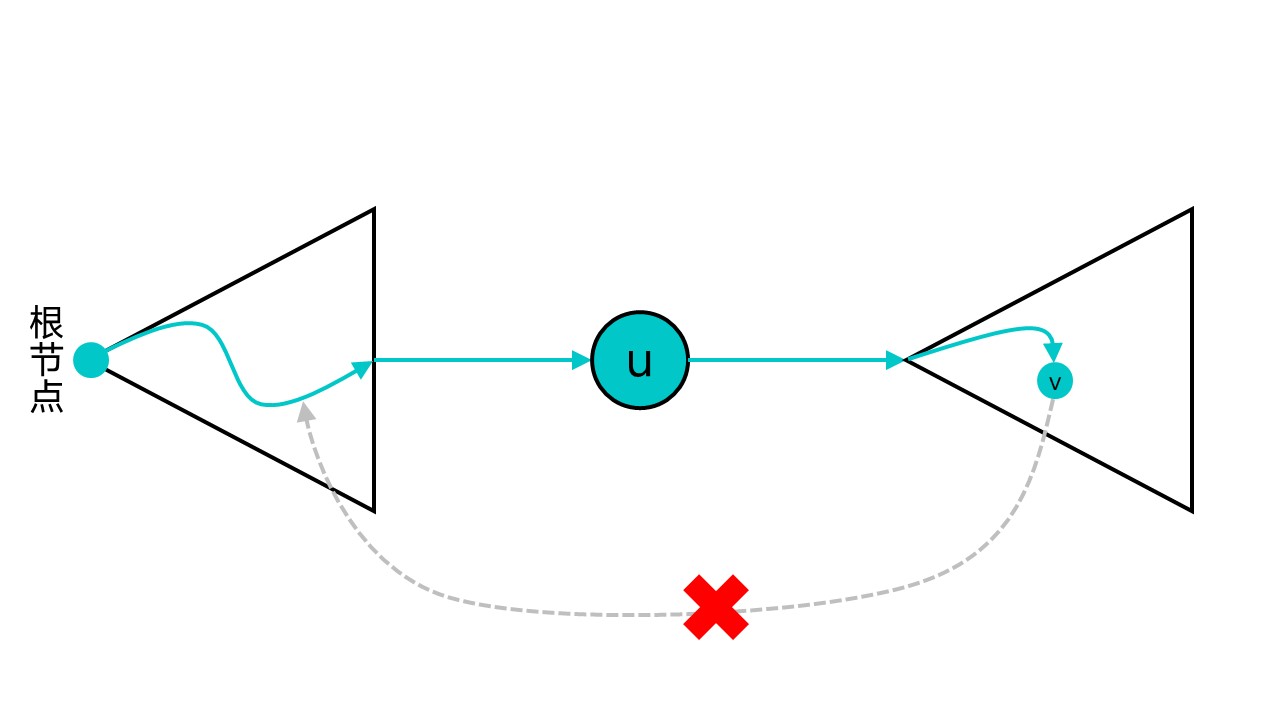
- u不为DFS树的树根,且对于u在DFS树中的任意一个后代v,都必须先经过u才能通往u的祖先,如图(蓝绿色箭头代表DFS路径):
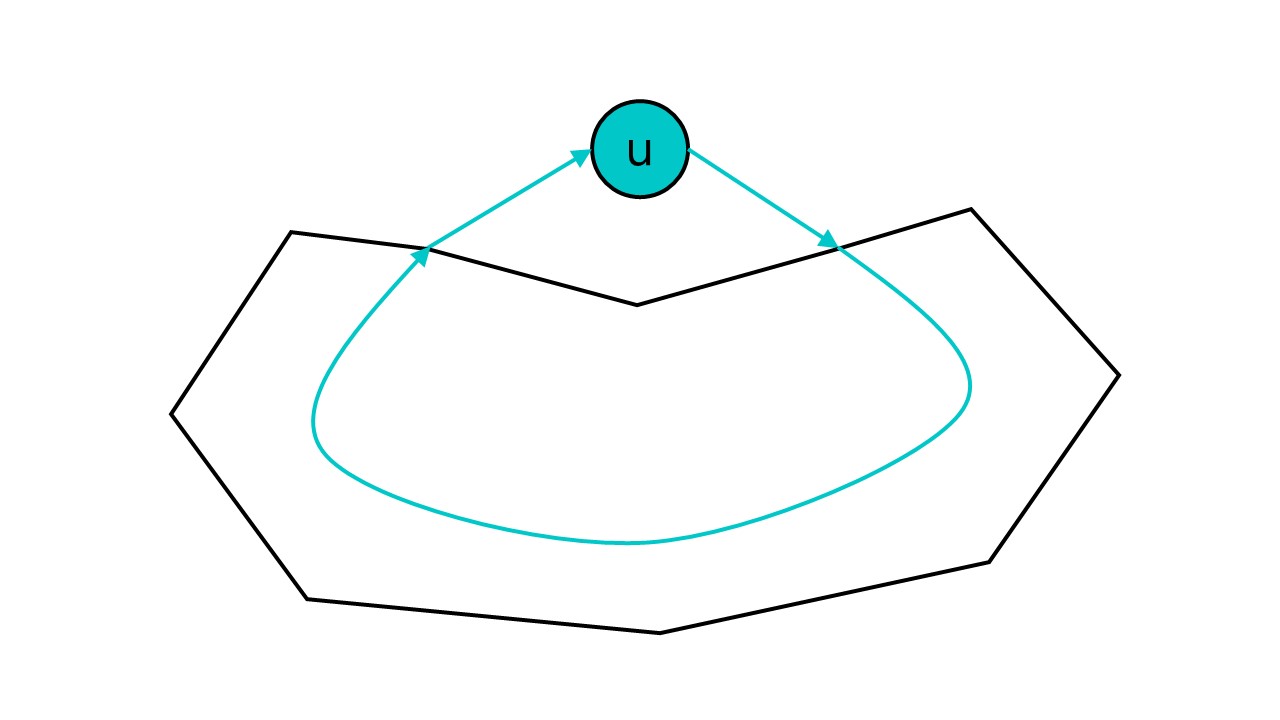
注意第一点并不等价于u有2个及以上的邻居,因为这些邻居有可能处于同一个DFS树,比如下面这张图,u有2个邻居,但却只有一个子树,因此u不是整个图的割点。
第二点也不难理解,如果v必须先经过u才能到达u的祖先的话,那么去掉u就无路可走了,连通分支数会增加,u就是割点。
DFS
我们可以维护两个数组:dfn和low,其中:
dfn[u]代表u被遍历到的次序(时间戳)。如果节点u先于节点v被访问,那么dfn[u] < dfn[v]。规定根节点的dfn为1。low[u]代表从u的后代出发,在不经过父节点的情况下能够“另辟蹊径”回溯到的最先遍历到的祖先的dfn。(每一步都不能走到当前走到的节点的父节点,且走到某个祖先就马上记录low)
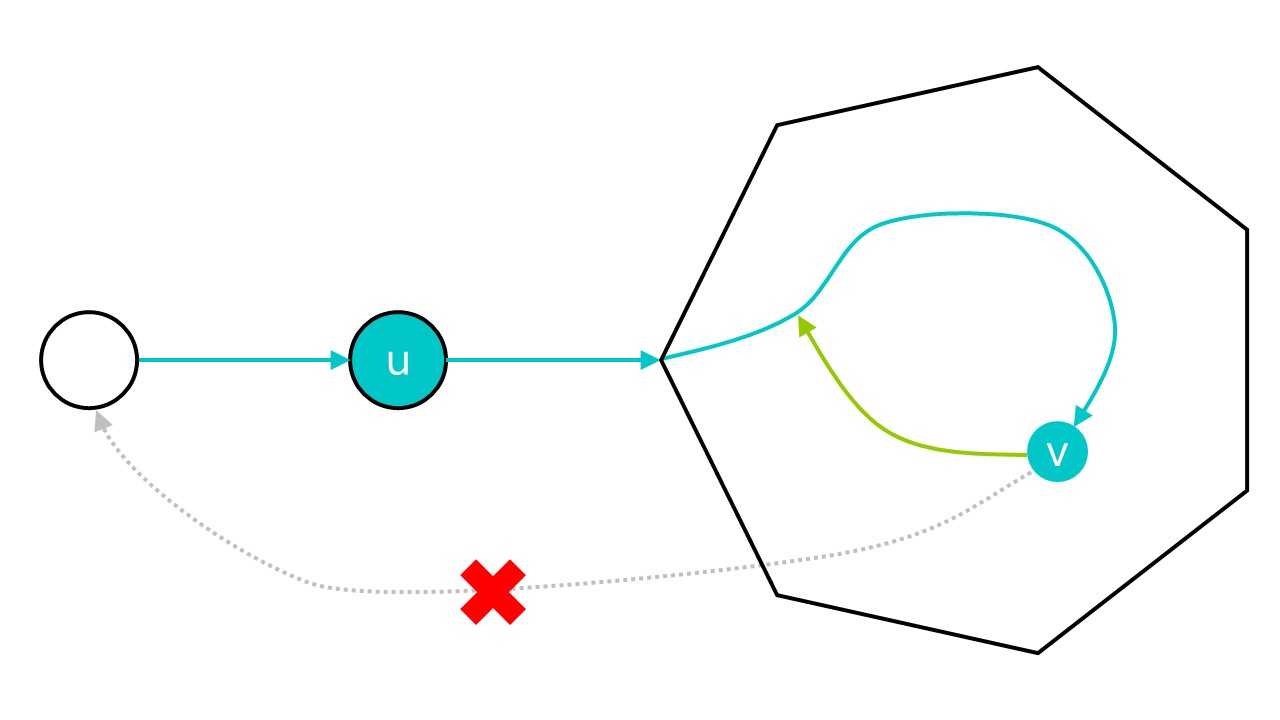
设u、v分别为DFS树中的两个节点,且v是u的后代,那么如果low[v] >= dfn[u],那么从v不经过父节点是走不到u的祖先的,则u就是割点,如图所示。(蓝绿色箭头表示DFS路径,黄绿色箭头表示回溯路径)
举个栗子吧。以下面这张图为例:
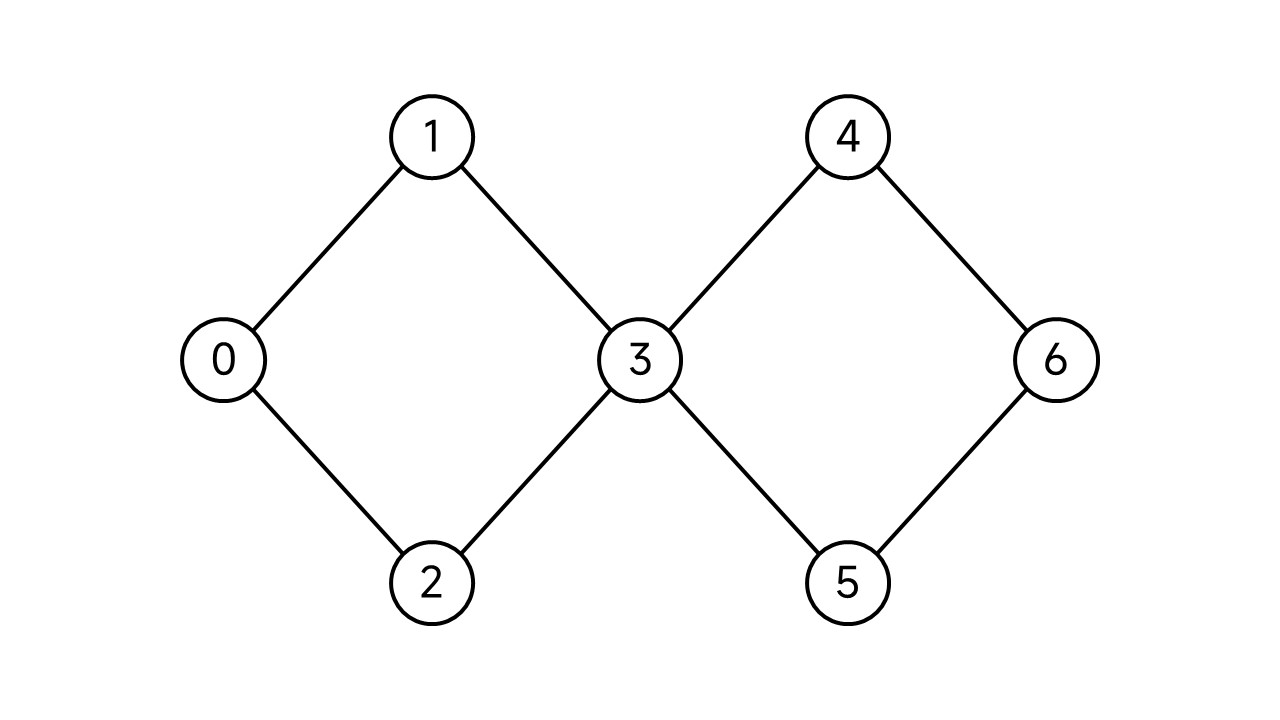
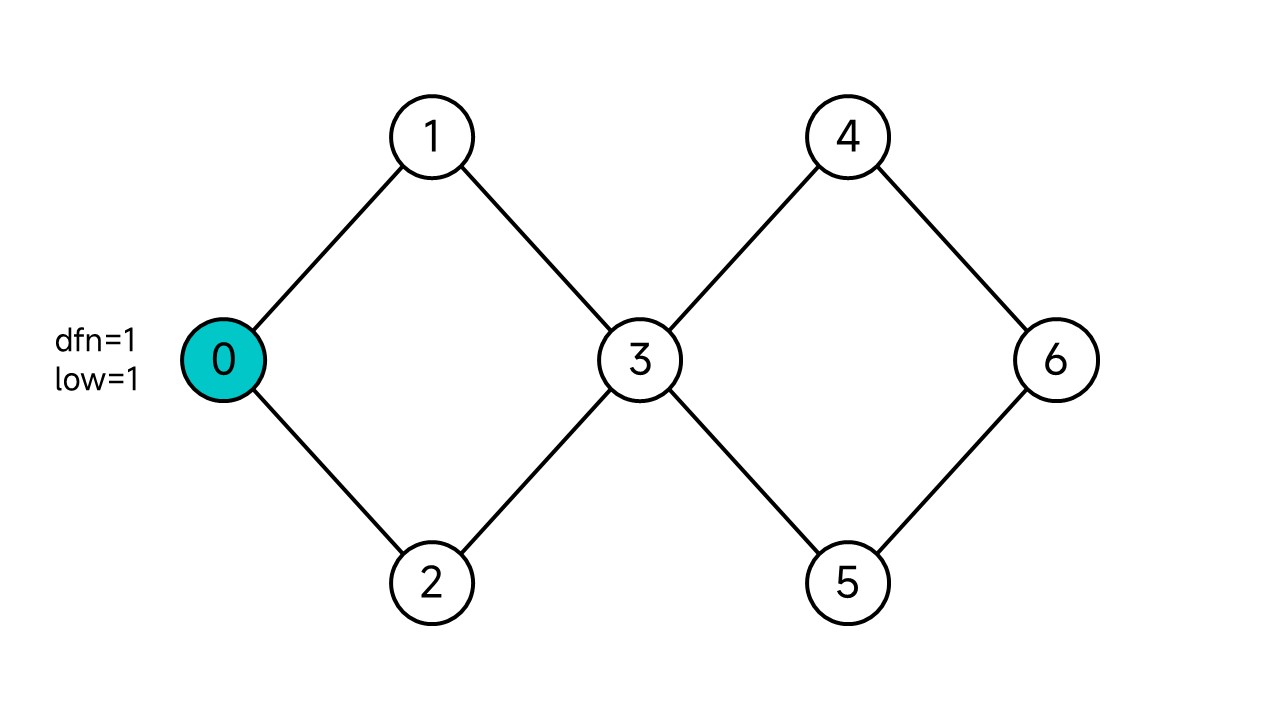
从节点0开始DFS。因为节点0是最开始遍历的节点,因此它的dfn和low均为1。
节点0有两个子节点,不妨先从1开始。因为我们还没有走到3和2,所以我们将1的low暂定为2。
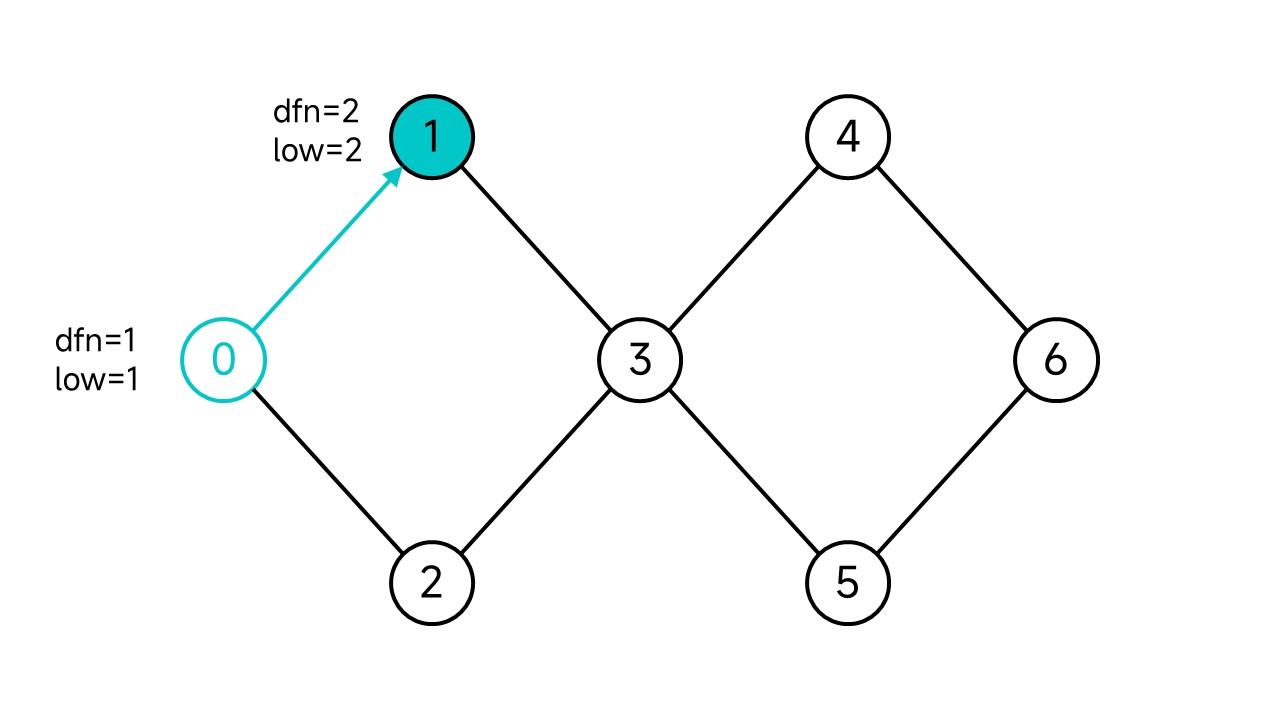
继续走下去:

节点3有3个子节点,先从节点4开始DFS。中间过程省略,直接一步到位走到5:
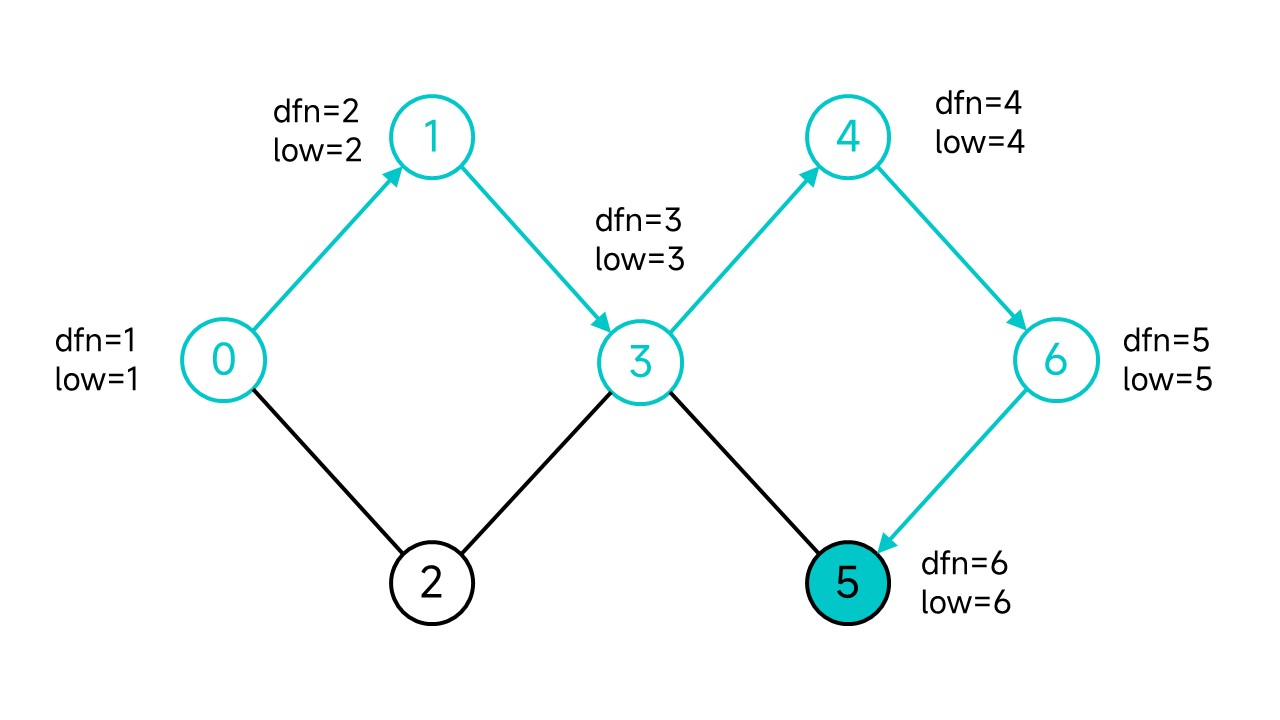
因为从5开始可以不经过父节点直接走到祖先3,将5的low更新为3。回溯到4,因为5是4和6的后代,按照low的定义,同样的可以将low更新为3。
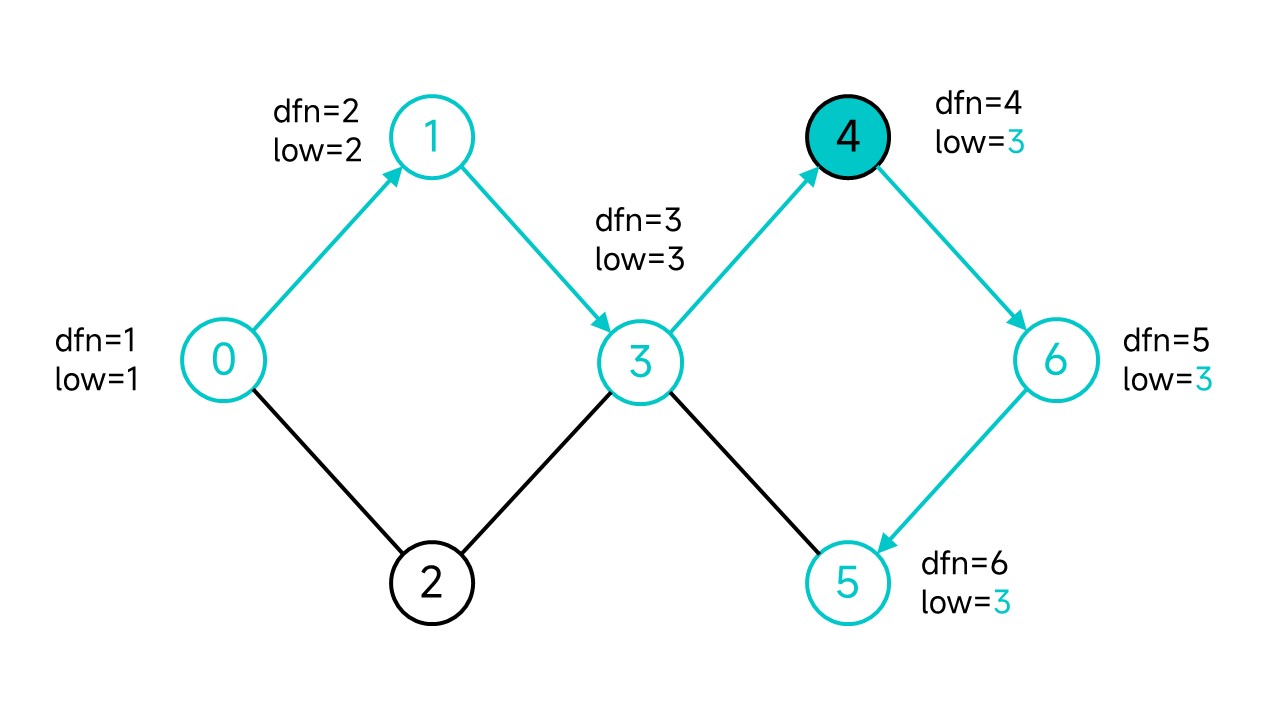
继续回溯到3,由于4和5都已经访问过了,还剩2没访问,先走到2。
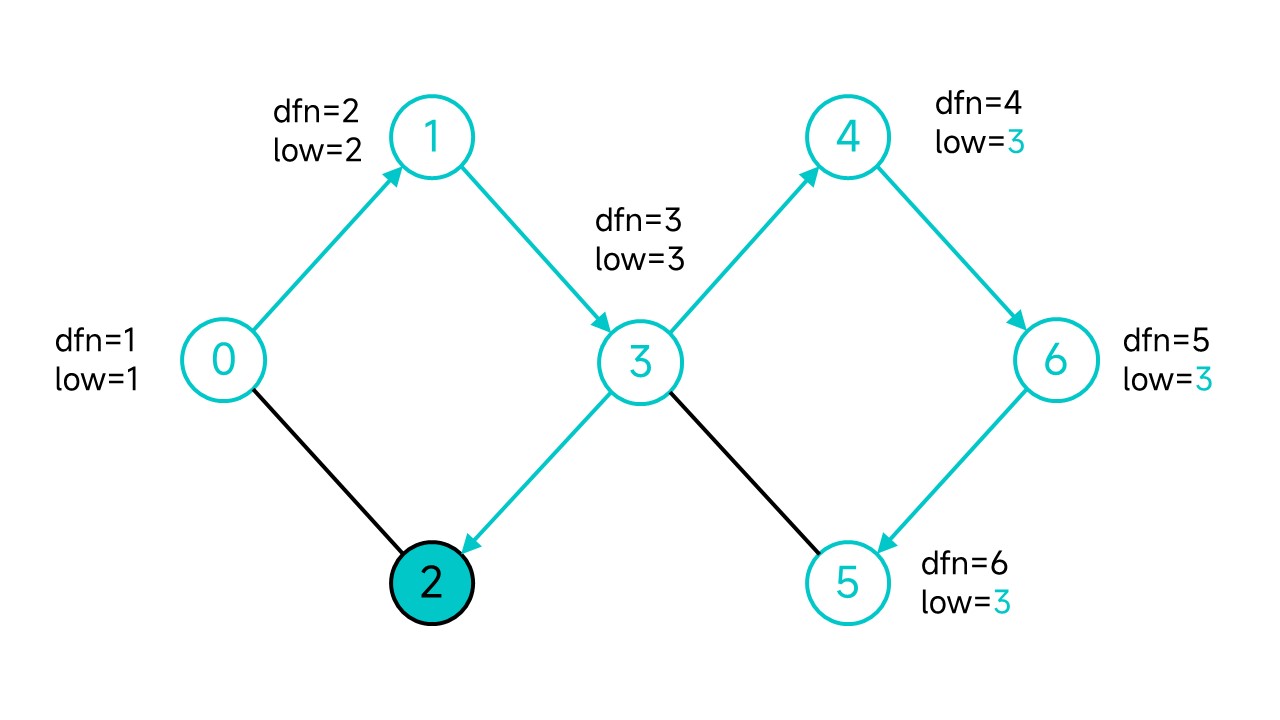
从2可以不经过父节点直接走到0,更新2的low为1;回溯的时候也将相应节点的low更新为1。
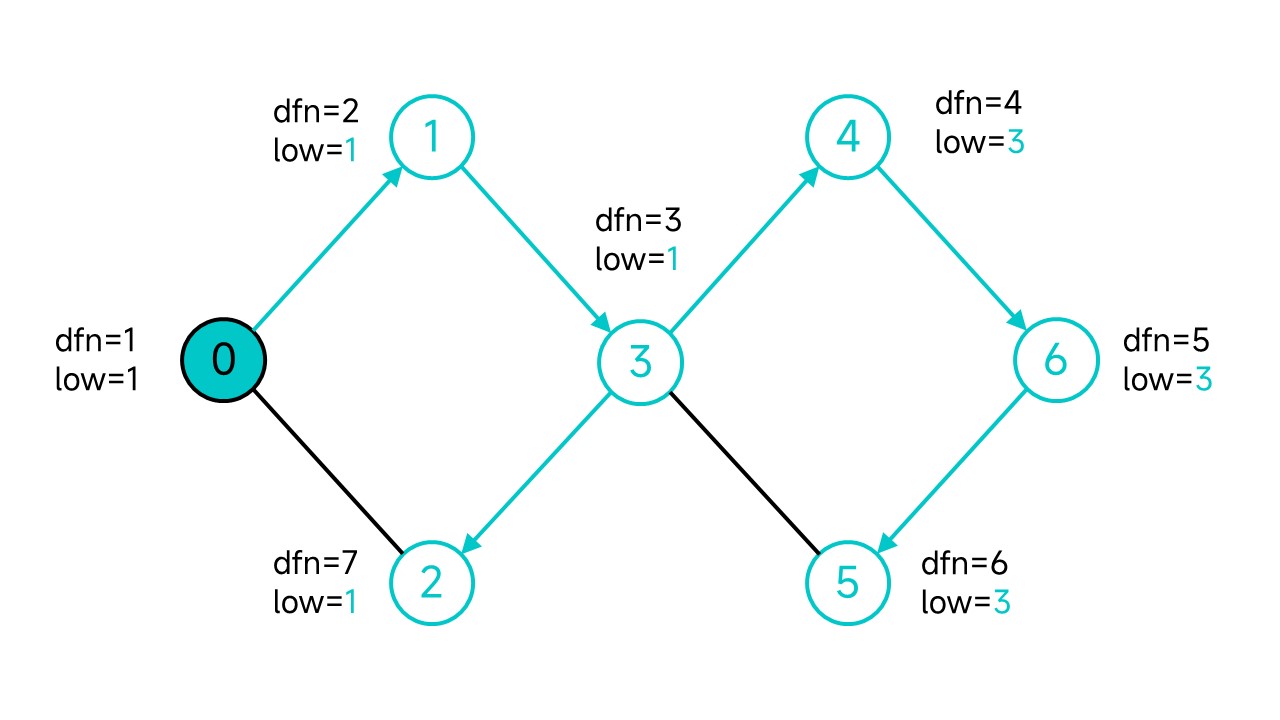
由此可以得到一个所有节点的dfn和low的表格(按dfn由小到大排序):
| 节点 | dfn | low |
|---|---|---|
| 0 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 1 |
| 4 | 4 | 3 |
| 6 | 5 | 3 |
| 5 | 6 | 3 |
| 2 | 7 | 1 |
对于节点3来说,因为它的所有后代4、6、5的low均等于3的dfn,所以从这些节点出发不经过父节点是不能走到3的祖先的,因此3是整幅图的割点。
代码实现
首先给出两个类型别名:node_t和order_t,用以使语义更加明确:
using node_t = unsigned long long;
using order_t = unsigned long long;
因为这里主要利用两个顶点之间的邻接关系,这里图使用邻接表来表示:
class Graph {
unsigned long long n;
vector<vector<node_t>> adj;
protected:
void dfs(node_t cur, node_t parent, vector<order_t> &dfn, vector<order_t> &low, order_t &order, unordered_set<node_t> &aps);
public:
Graph(initializer_list<initializer_list<node_t>> list) : n(list.size()), adj({}) {
for (auto &l : list) {
adj.emplace_back(l);
}
}
unordered_set<node_t> findAP();
};
“寻找割点”的代码整体框架:
unordered_set<node_t> Graph::findAP() {
vector<order_t> dfn(n, 0); // 未被访问过的节点的dfn和low初始化为0
vector<order_t> low(n, 0);
order_t order = 0;
unordered_set<node_t> aps;
node_t root = 0;
dfs(root, -1, dfn, low, order, aps);
return aps;
}
DFS的大体框架:
void Graph::dfs(node_t cur, node_t parent, vector<order_t> &dfn, vector<order_t> &low, order_t &order, unordered_set<node_t> &aps) {
size_t children = 0; // 当前节点的子树数量
dfn[cur] = low[cur] = ++order;
for (node_t neighbor: adj[cur]) {
if (dfn[neighbor] == 0) {
children++;
dfs(neighbor, cur, dfn, low, order, aps);
// ...
} else {
// ...
}
}
}
其中部分形参代表的意义:
cur:当前遍历到的节点。parent:当前节点的父节点(根节点的父节点规定为-1)order:遍历到的次序。aps:储存割点的集合。
问题来了,low怎么计算。
假设当前遍历到的节点u的某一个邻居为v:
- 若v为u的子节点,则
low[u]更新为low[u]与low[v]取最小值。 - 若v不为u的子节点,也不是u的父节点,则说明从u出发可以不经过父节点直接到达v,此时
low[u]更新为low[u]与dfn[v]的最小值。
代码实现如下:
if (dfn[neighbor] == 0) {
// ...
low[cur] = min(low[cur], low[neighbor]);
// ...
} else if (neighbor != parent) {
low[cur] = min(low[cur], dfn[neighbor]);
}
割点的判定,上文已有提及,直接上代码:
if (dfn[cur] == 1 && children > 1 || dfn[cur] > 1 && low[neighbor] >= dfn[cur]) {
aps.insert(cur);
}
完整代码:
void Graph::dfs(node_t cur, vector<order_t> &dfn, vector<order_t> &low, order_t &order, unordered_set<node_t> &aps) {
size_t children = 0;
dfn[cur] = low[cur] = ++order;
for (node_t neighbor: adj[cur]) {
if (dfn[neighbor] == 0) {
children++;
dfs(neighbor, dfn, low, order, aps);
low[cur] = min(low[cur], low[neighbor]);
if (dfn[cur] == 1 && children > 1 || dfn[cur] > 1 && low[neighbor] >= dfn[cur]) {
aps.insert(cur);
}
} else if (neighbor != parent) {
low[cur] = min(low[cur], dfn[neighbor]);
}
}
}
测试:
int main() {
Graph graph{{1, 2},
{0, 3},
{0, 3},
{1, 2, 4, 5},
{3, 6},
{3, 6},
{4, 5}};
auto aps = graph.findAP();
cout << "The articulation points are:" << endl;
for (node_t ap: aps) {
cout << ap << ' ';
}
cout << endl;
return 0;
}
输出:
The articulation points are:
3
复杂度分析
- 时间复杂度:\(O(n+e)\),其中 \(n\) 代表节点数,\(e\) 代表边数,DFS的时间复杂度为\(O(n+e)\)。
- 空间复杂度:\(O(n+e)\),其中 \(n\) 代表节点数,\(e\) 代表边数,邻接表的空间复杂度为 \(O(n+e)\),维护的数组的空间复杂度为 \(O(n)\),加起来为 \(O(n+e)\)。