大佬的TensorFlow代码:here
另一个大佬的Pytorch代码:here
注:Pytorch代码只有semanticKITTI的训练,TensorFlow作者本人的代码比较全。
keywords
在正式开始讲论文之前,我们先看看效果, 0.04s的inference time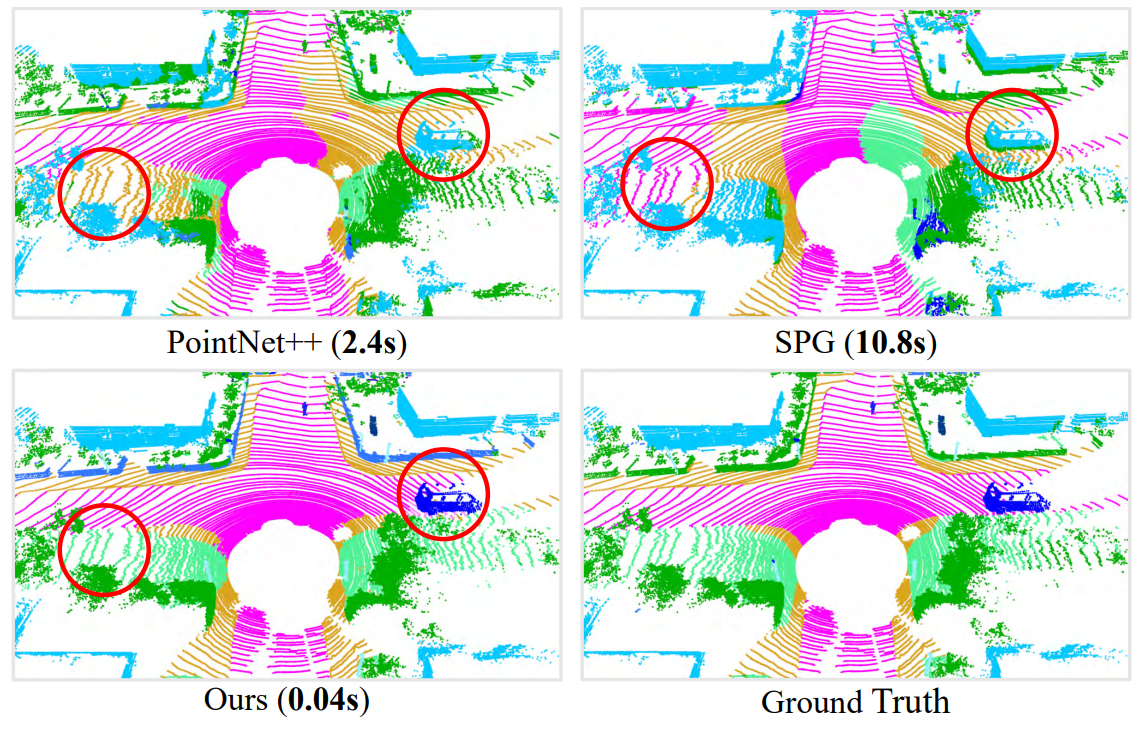
那么咱们正式开始
相关工作
\(_{*篇幅有限,此处不再介绍其他基于投影或基于体素的工作}\)
PointNet++
-
网络结构
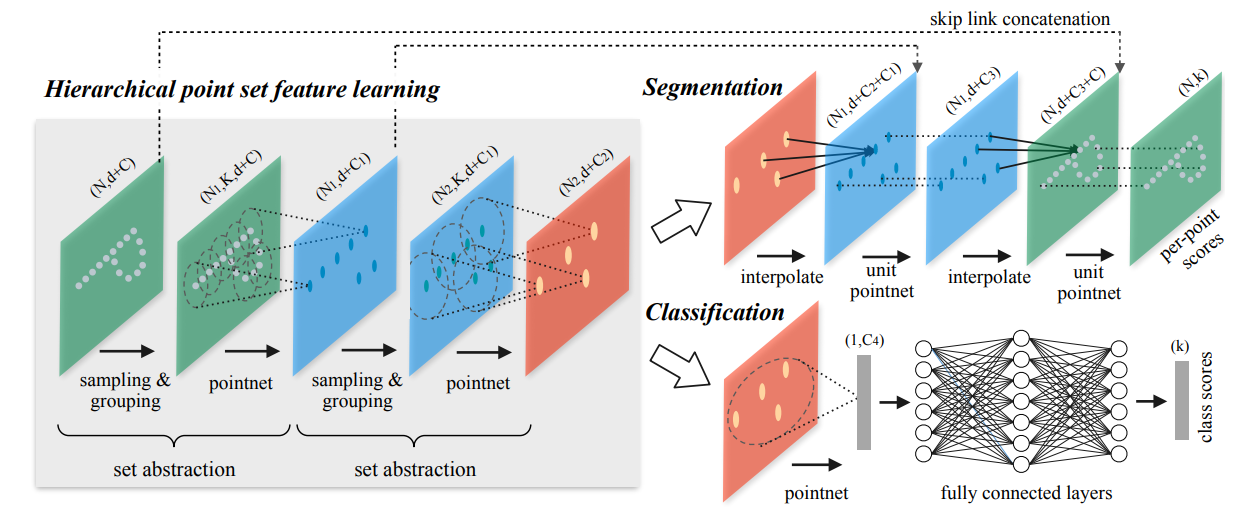
-
关键组件
- Samping——FPS(最远点采样)
顾名思义,每次在点云中采样的点都应该距其他点的距离最远
举个例子,下图,一个二维欧式空间中,我们需要使用FPS采样4个点;最简单的步骤是:1、从七种颜色中随机选择一个 [例,选择二项限的橙猫猫]
2、寻找距橙猫猫最远的点(欧式距离) [选择一象限的小紫]
3、寻找距离小紫和橙猫猫都最远的点 [选择三象限的淡淡色]
4、重复上述步骤,直到采样完成 [最后应该选择四象限的小绿]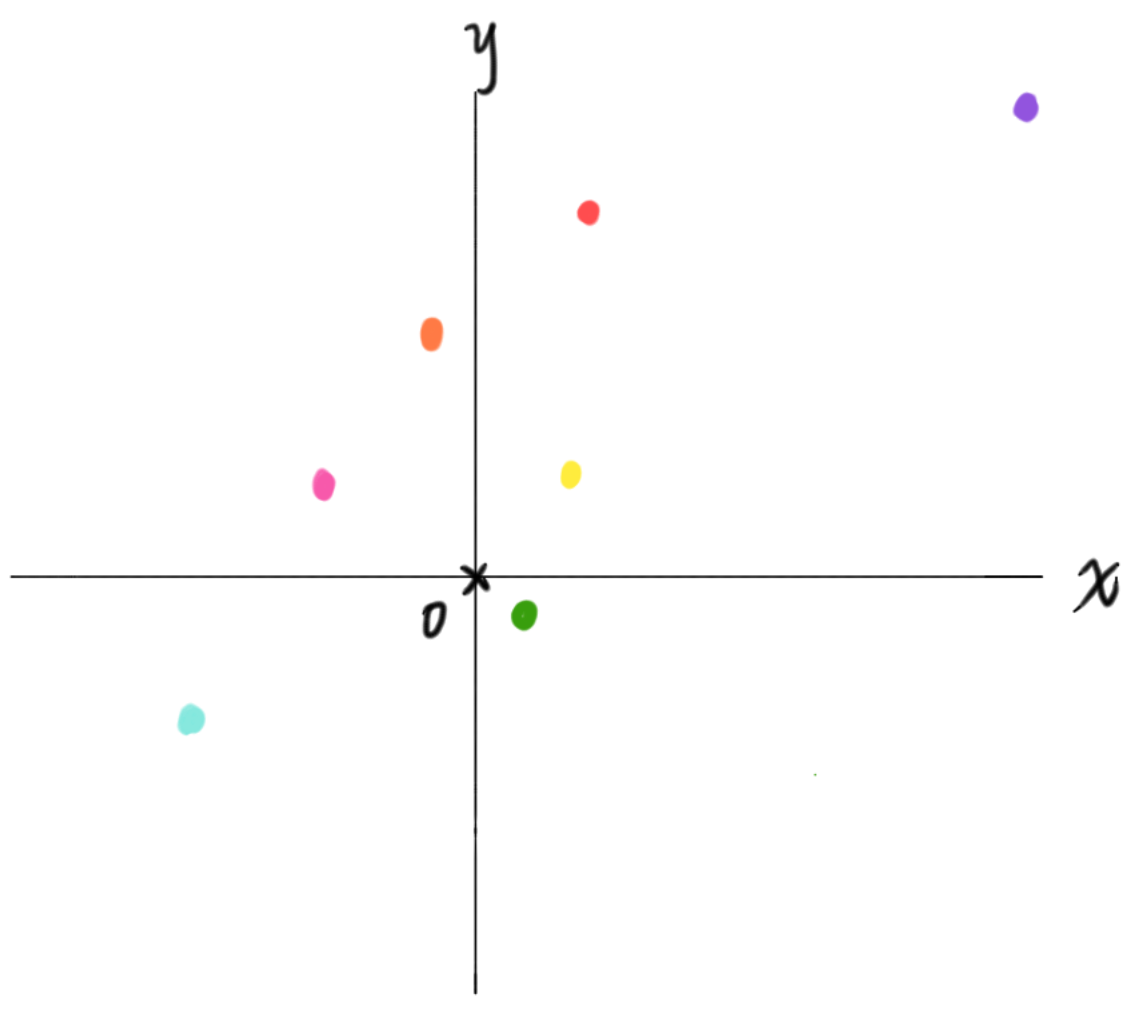
优点:能够尽可能覆盖空间中的所有点
缺点:计算复杂度高下图为一张使用FPS得到的采样点
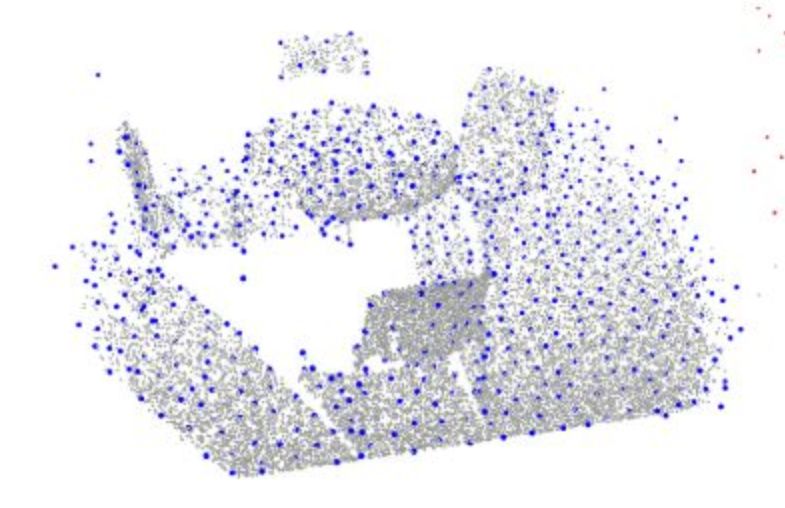
- Grouping——ball_query(球查询)
PointNet++的思路为:在原始点云中采样若干点(后称Centroids),并在Centroids邻域里采样K个点(包括Centroids)构成分组,然后在每个分组内使用PointNet;FPS已经完成了第一步,现在,我们继续使用ball_query找到Centroids周围的K个点
较于ball_query,大家肯定更熟悉KNN这个算法,所以我们先从KNN入手:1、计算周围点和Centroids的距离 [如果使用xyz坐标,就是在欧式空间中的距离;如果使用网络在本层的特征向量,那么就是特征空间中的距离]
2、每次将距离最近的点与Centroids归为同一组
3、重复,直到采集到K个点ball_query与KNN的区别则在于:ball_query增加了一个参数radius,约束采样点必须在一定半径的球域上,当球域内的点≥待采点K时,同KNN;反之,直接用第一个点的特征补全。
PointCNN
- 网络结构
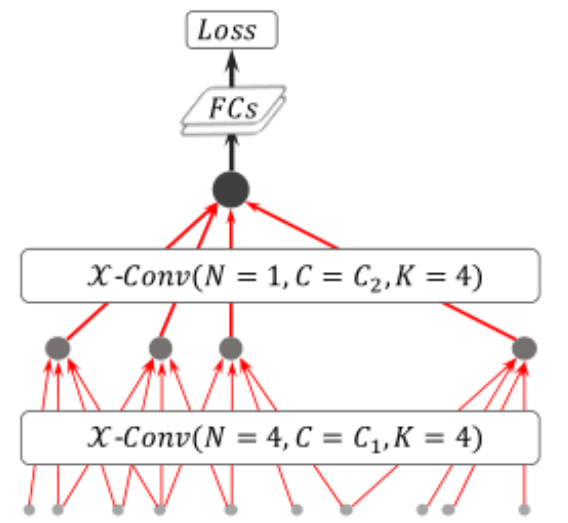
- 说明
-
由于PointCNN与PointNet++在采样和分组时使用的方法基本相同,即FPS和KNN,此处不再说明,主要就其对于卷积结构的改进进行一些说明。
在这之前,咱们需要明确一下点云的置换不变性,置换不变性是指点云不管以何种顺序输入网络,都应该得到相同的结果,所以PointNet++使用了PointNet作为每个分组的处理网络,但PointNet这种对每个点单独处理的网络注定不能取得很好地效果;所以,这篇文章提出了一种在点云中的卷积结构,既保证了置换不变性,也能更好地利用邻域内的特征,\(\mathcal{X}conv\)算法如下:
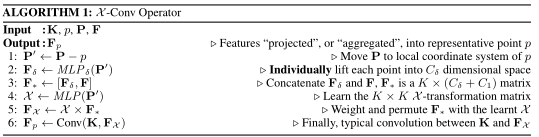
-
RandLA-Net
对采样策略的分析改进
- 启发式的采样策略
| 采样方式 | Farthest Point Sampling (FPS) | Inverse Density Importance Sampling (IDIS) | Random Sampling (RS) |
|---|---|---|---|
| 复杂度 | \(\mathcal{O}(N^2)\) | \(\mathcal{O}(N)\) | \(\mathcal{O}(1)\) |
- 基于学习的采样策略
| 采样方式 | Generator-based Sampling (GS) | Continuous Relaxation based Sampling (CRS) | Policy Gradient based Sampling (PGS) |
|---|---|---|---|
| 存在问题 | 效率太低 | 内存占用大 | 在大规模点云上难以收敛 |
\(_{*部分采样方式我也没用过,各位如果对这部分感兴趣的可以去看看其他教程,我就不在这误人子弟了}\)
可以看出,FPS、IDIS和GS等方法在大规模点云上的效率很低;CRS和PGS等方法也会出现其他问题;所以,作者最后选择了随机的采样策略(即RS),虽然随机采样会带来采样不均匀、丢失关键点等问题,但起码保证了采样过程的效率和稳定性。
网络结构


这部分可以被看作结构中的一个layer,我们按照处理顺序对结构进行分析
- Local Spatial Encoding
- 首先,对于输入,这是我们每次通过随机采样后得到的点Input.shape=(N, 3+d),每个点特征维中的3代表其xyz坐标,后面的d代表特征维度。
- 接下来,使用KNN采集每个采样点周围的近邻点(欧氏距离),并将其分组,Grouping.shape=(N, K, 3+d)。
- 现在,我们已经完成了采样和分组这两步,得到了N个局部点集,接下来,我们需要对每个局部做处理。
- 对每个组内的特征,LocalFeature.shape=(K, 3+d),我们将坐标和特征分开处理(实际上,在代码中这部分是分别输入的),对坐标,我们计算每个点和Centroids之间的各种距离,并将这些距离通过concat连接起来,实验证明,这种冗余特征是有益于模型学习的;将这些通过一个MLP后,我们最后得到\(r_{i}^{k}\).shape=(K, d)的特征,公式如下: \(r_{i}^{k}=MLP(p_{i}\oplus p_{i}^{k}\oplus (p_{i}-p_{i}^{k})\oplus ||p_{i}-p_{i}^{k}||)\),将\(r_{i}^{k}\)与\(f_{i}^{k}\)concat起来,我们就得到了组内各点的局部编码。
这一模块的功能是:将组内各点的位置特征进行一定处理之后,与各点原本特征concat,丰富了模型可学习的特征,代码实现如下:
f_xyz = self.relative_pos_encoding(xyz, neigh_idx) # centroids和周围点的相对位置编码
f_xyz = f_xyz.permute((0, 3, 1, 2)) # 转置,输入MLP
f_xyz = self.mlp1(f_xyz)
f_neighbours = self.gather_neighbour(feature.squeeze(-1).permute((0, 2, 1)), neigh_idx)
f_neighbours = f_neighbours.permute((0, 3, 1, 2))
f_concat = torch.cat([f_neighbours, f_xyz], dim=1)# 获取周围近邻点的特征,转置,与位置编码拼接
- Attentive Pooling
实际上,这个部分就相当于PointNet中的MaxPooling结构,如果我们不讨论内部结构,那么这个模块完成的任务就是将\(\hat{f_{i}^{k}}\).shape=(K, 2d)通过pooling变为output.shape=(1, d’),后面作者也做了实验证明了他提出的Attnpool确实更有效。
formula of maxpool and attnpool
\(maxpool = \max(Linear(feature))\)
\(attnpool = Linear\{\sum[feature\odot softmax(Linear(feature))]\}\)
上述公式描述了Attentive pooling的实现,可以发现,作者使用类似注意力机制的方式得到了各特征各分量的注意力得分,使用element-wise multiplication与feature相乘。下面是代码实现,很简单。
class Att_pooling(nn.Module):
def __init__(self, d_in, d_out):
super().__init__()
self.fc = nn.Conv2d(d_in, d_in, (1, 1), bias=False)
self.mlp = pt_utils.Conv2d(d_in, d_out, kernel_size=(1, 1), bn=True)
def forward(self, feature_set):
att_activation = self.fc(feature_set)
att_scores = F.softmax(att_activation, dim=3)
f_agg = feature_set * att_scores
f_agg = torch.sum(f_agg, dim=3, keepdim=True)
f_agg = self.mlp(f_agg)
return f_agg
至此,我们完成了RandLA-Net中基本单元的构建,我们姑且把它称为RandLA-Net Vanilla(笑),接下来就像ResNet一样,往上堆layer就行了(暴言)
- Dilated Residual Block
这部分在结构上没啥内容可讲,实际上就是两层RandLA-Net Vanilla加上一个残差连接而已;剩下的内容留到实验部分一起说。

在讲实验之前,先来看看整体的模型结构先,确实是堆layer(笑)

实验
\(_{*作者的训练设备AMD 3700X @3.6GHz CPU + NVIDIA RTX2080Ti GPU.}\)
-
关于各种采样方式的效率
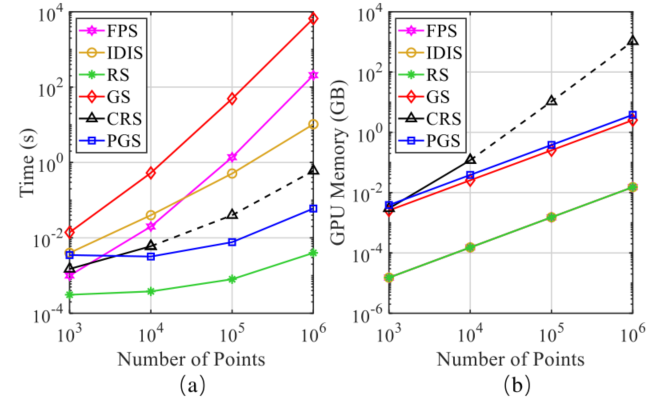
很直观,可以看到随机采样在效率和内存占用上都有非常优秀的表现 -
消融实验

对这个表做一些解释:
(1)去掉LocalSE模块
可以看出,去掉LocalSE模块后,对mIoU的影响较大,因为这种组内的局部几何关系在点云中是很有必要的;之前也提到,PointNet就缺少这种点与点之间的几何关系特征。
(2~4)将AttnPool换为Max、Mean、SumPool
证明了作者的AttnPool要优于其它池化方式
(5)简化残差模块
不知道各位是否还记得之前我们埋的坑?随机采样的策略可能会导致关键点的丢失,从而导致模型效果不好这里作者分析,如果使用两层RandLA-Net Vanilla之后再进行残差连接,那么每个采样点都会学到周围\(K^2\)范围内的点特征[可以理解为感受野],感受野大了,采样点能够学到关键点的概率也就增大了;所以,效果也就更好。
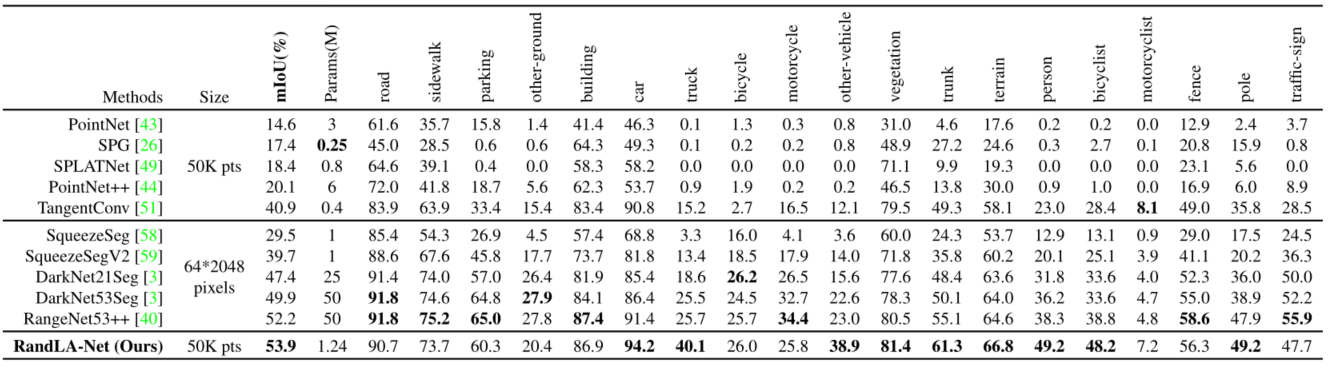
- 对比实验
无非是突出了自己的方法使用的点云规模更大,效果更好了。毕竟是顶会,没点SOTA怎么行。
写在最后
姑且算是讲完了,我也要去跑复现了,到时候有心得就再开一坑。PS:没想到搞复现最难的不是看代码,是下数据集,semanticKITTI…?校园网流量不够了。