一:背景
1. 讲故事
前段时间有位朋友微信找到我,说他的程序使用 hsl 库之后,采集 plc 时内存溢出,让我帮忙看一下怎么回事,哈哈,貌似是分析之旅中的第二次和 hsl 打交道,既然找到我,那就上 windbg 说话吧。
二:WinDbg 分析
1. 为什么会内存溢出
简单观察程序的提交内存之后,发现内存的 Stack 区非常大,随用 !t 看了下到底有多少个线程,截图如下:
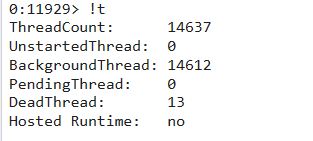
不看不知道,一看吓一跳,这个程序居然有近 1.5w 的线程,虽然我见过大世面(3w+线程),但还是心有余悸,随用 ~*e !clrstack 看了下各个线程都在做什么,经过一顿观察,发现线程都卡在 Interactivelock.Enter 锁上,截图如下:

从代码中看,理论上存在 Interactivelock.Enter() 和 Interactivelock.Leave() 因为各种异常导致锁的不成对进而造成锁污染的情况,看起来是 hsl 代码不严谨造成的什么 bug,观察了下版本也不是最新的,而且最新版的锁这块也修改了逻辑,就让朋友升级下 hsl 再观察看看,看样子这个问题应该轻松搞定了,不过我保守的说了下,如果还是遇到大量的线程,可以随时联系我。
2. 真的搞定的吗
过了一天这位朋友又找到我,说把 hsl 升级到最新版本之后还是出现了大量线程,让我再看一下,继续用 ~*e !clrstack 观察各个线程栈,发现还是卡在 pipeSocket.PipeLockEnter() 这里,这就很迷了,代码如下:
OS Thread Id: 0x1144 (21)
Child SP IP Call Site
...
000000A1AFF3DE90 00007ffa9cac6e05 System.Net.Sockets.SocketPal.Connect(System.Net.Sockets.SafeSocketHandle, Byte[], Int32) [/_/src/System.Net.Sockets/src/System/Net/Sockets/SocketPal.Windows.cs @ 118]
000000A1AFF3DEE0 00007ffa9cac6c52 System.Net.Sockets.Socket.DoConnect(System.Net.EndPoint, System.Net.Internals.SocketAddress) [/_/src/System.Net.Sockets/src/System/Net/Sockets/Socket.cs @ 4415]
000000A1AFF3DF30 00007ffa9cac6a63 System.Net.Sockets.Socket.Connect(System.Net.EndPoint) [/_/src/System.Net.Sockets/src/System/Net/Sockets/Socket.cs @ 810]
000000A1AFF3DF80 00007ffa9b7bc75a HslCommunication.Core.NetSupport.CreateSocketAndConnect(System.Net.IPEndPoint, Int32, System.Net.IPEndPoint)
000000A1AFF3DFF0 00007ffa9cac8768 HslCommunication.Core.Net.NetworkBase.CreateSocketAndConnect(System.Net.IPEndPoint, Int32, System.Net.IPEndPoint)
000000A1AFF3E030 00007ffa9cac84ba HslCommunication.Core.Net.NetworkDoubleBase.CreateSocketAndInitialication()
000000A1AFF3E070 00007ffa9cac83b8 HslCommunication.Core.Net.NetworkDoubleBase.ConnectServer()
000000A1AFF3E0B0 00007ffa9c697f8b HslCommunication.Core.Net.NetworkDoubleBase.GetAvailableSocket()
000000A1AFF3E0F0 00007ffa9c697545 HslCommunication.Core.Net.NetworkDoubleBase.ReadFromCoreServer(Byte[], Boolean, Boolean)
000000A1AFF3E160 00007ffa9c6a2779 HslCommunication.Profinet.Siemens.SiemensS7Net.ReadS7AddressData(HslCommunication.Core.Address.S7AddressData[])
000000A1AFF3E1A0 00007ffa9bfedef5 HslCommunication.Profinet.Siemens.SiemensS7Net.Read(System.String, UInt16)
...
0:021> !dso
OS Thread Id: 0x1144 (21)
RSP/REG Object Name
000000A1AFF3E058 00000280c8ca33d8 HslCommunication.Profinet.Siemens.SiemensS7Net
000000A1AFF3E0C0 00000281c9150e58 Microsoft.Win32.SafeHandles.SafeWaitHandle
...
0:021> !gcroot 00000281c9150e58
Thread 1144:
-> 00000280C8CA37E8 HslCommunication.Core.SimpleHybirdLock
-> 00000280C8CA3860 System.Lazy`1[[System.Threading.AutoResetEvent, System.Private.CoreLib]]
-> 00000281C9150E40 System.Threading.AutoResetEvent
-> 00000281C9150E58 Microsoft.Win32.SafeHandles.SafeWaitHandle
0:021> !do 00000280C8CA37E8
Name: HslCommunication.Core.SimpleHybirdLock
Fields:
MT Field Offset Type VT Attr Value Name
00007ffa998a71d0 4000162 14 System.Boolean 1 instance 0 disposedValue
00007ffa998ab1f0 4000163 10 System.Int32 1 instance 614 m_waiters
00007ffa9bcea5e0 4000164 8 ...Private.CoreLib]] 0 instance 00000280c8ca3860 m_waiterLock
00007ffa998ac570 4000165 2e8 System.Int64 1 static 859 simpleHybirdLockCount
00007ffa998ac570 4000166 2f0 System.Int64 1 static 857 simpleHybirdLockWaitCount
从上面的 m_waiters=614 来看,当前有 614 个线程在等待,这里要稍微吐槽一下,建议封装 SimpleHybirdLock 的时候最好记录下当前谁在持有这个锁,不然找起来太难了。。。
经过一顿摸索发现是 21号 线程正在持有 SimpleHybirdLock,正在调用 GetAvailableSocket 方法出不来,截图如下:
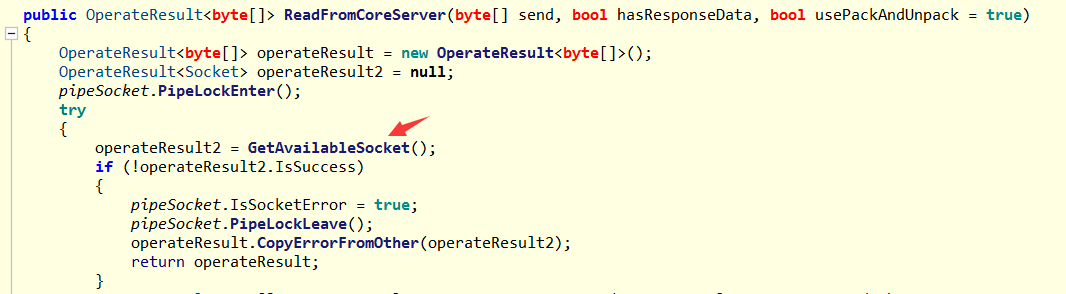
3. 为什么获取不到 Socket
既然有 600+ 线程在等待,大概率在获取可用 Socket 上出了什么问题,有了这个思路我们用 !dso 去找下 Socket 的 IP 地址是什么,看看dump中有没有什么异常。
0:021> !dso
OS Thread Id: 0x1144 (21)
RSP/REG Object Name
000000A1AFF3E350 00000281c8ac61a8 System.Object[] (System.Object[])
000000A1AFF3EA38 00000281c9c80608 System.String 172.16.3.208
....
提取到 IP 地址之后,接下来到用 !strings 到 dump 中搜一下可有这个 ip 相关的信息,果不其然,发现有大量的 IP 超时,截图如下:
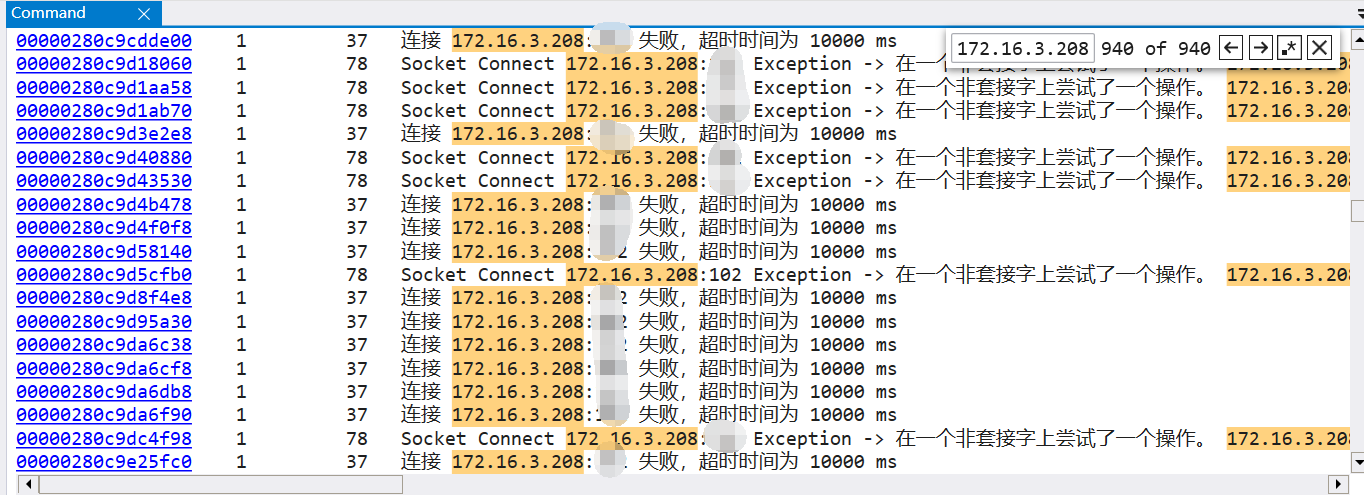
到这里我们大概就知道了,原来是程序跑着跑着,由于网络等各方面的问题导致 IP 不可访问,进而引发程序系统性崩盘。
4. hsl 真的很无辜吗
这里没有任何针对性,只是从技术上进行一下探讨,先上一下 hsl 对这块的处理,简化后如下:
public OperateResult<byte[]> ReadFromCoreServer(byte[] send, bool hasResponseData, bool usePackAndUnpack = true)
{
OperateResult<byte[]> operateResult = new OperateResult<byte[]>();
OperateResult<Socket> operateResult2 = null;
pipeSocket.PipeLockEnter();
try
{
operateResult2 = GetAvailableSocket();
if (!operateResult2.IsSuccess)
{
pipeSocket.IsSocketError = true;
pipeSocket.PipeLockLeave();
operateResult.CopyErrorFromOther(operateResult2);
return operateResult;
}
ExtraAfterReadFromCoreServer(operateResult3);
pipeSocket.PipeLockLeave();
}
catch
{
pipeSocket.PipeLockLeave();
throw;
}
if (!isPersistentConn)
{
operateResult2?.Content?.Close();
}
return operateResult;
}
internal static OperateResult<Socket> CreateSocketAndConnect(IPEndPoint endPoint, int timeOut, IPEndPoint local = null)
{
int num = 0;
while (true)
{
num++;
Socket socket = new Socket(endPoint.AddressFamily, SocketType.Stream, ProtocolType.Tcp);
HslTimeOut hslTimeOut = HslTimeOut.HandleTimeOutCheck(socket, timeOut);
try
{
if (local != null)
{
socket.Bind(local);
}
socket.Connect(endPoint);
hslTimeOut.IsSuccessful = true;
return OperateResult.CreateSuccessResult(socket);
}
catch (Exception ex)
{
socket?.Close();
hslTimeOut.IsSuccessful = true;
if (hslTimeOut.GetConsumeTime() < TimeSpan.FromMilliseconds(500.0) && num < 2)
{
Thread.Sleep(100);
continue;
}
if (hslTimeOut.IsTimeout)
{
return new OperateResult<Socket>(string.Format(StringResources.Language.ConnectTimeout, endPoint, timeOut) + " ms");
}
return new OperateResult<Socket>($"Socket Connect {endPoint} Exception -> " + ex.Message);
}
}
}
从代码中可以看到,hsl 通过 catch 捕获到了异常,但并没有强制 throw 让用户自己做决断,而是吞到了 OperateResult 返回类中,用户层因为偷懒又没有判断这种异常状态导致了此问题的发生。 从逻辑看 Socket 是一个非常基础的功能,所以我觉得强制抛出更合理一点,逼迫用户可以更早的强制介入。
5. 为什么会有那么多线程
其实还留了一个问题没有解答,那就是为什么会产生那么多的线程,很显然这是一个 hsl 强吞异常导致的副作用,上层没有判断 OperateResult 的异常码,以为一切都 ok,继续它的周期性调度,被迫生成更多的线程池线程去赴死,危机重重,那具体是怎么调度的呢?可以观察各个线程的创建时间即可。
0:021> ~*e .printf "tid=%x\n",@$tid ; .ttime
...
Created: Thu Mar 9 09:02:05.541 2023 (UTC + 8:00)
Kernel: 0 days 0:00:00.062
User: 0 days 0:00:00.125
tid=38e8
Created: Thu Mar 9 09:02:10.540 2023 (UTC + 8:00)
Kernel: 0 days 0:00:00.015
User: 0 days 0:00:00.000
tid=2d64
Created: Thu Mar 9 09:02:15.540 2023 (UTC + 8:00)
Kernel: 0 days 0:00:00.015
User: 0 days 0:00:00.015
tid=3aa4
Created: Thu Mar 9 09:02:20.540 2023 (UTC + 8:00)
Kernel: 0 days 0:00:00.015
User: 0 days 0:00:00.000
tid=41ec
Created: Thu Mar 9 09:02:25.540 2023 (UTC + 8:00)
Kernel: 0 days 0:00:00.203
User: 0 days 0:00:00.218
...
从各个线程的创建时间来看,大概是 5s 采集一次。
三:总结
这次事故主要是由于在设备采集的过程中 IP 出了问题 导致的线程数暴涨引发的系统性崩溃,个人觉得朋友和hsl都有一定的责任,一个不检查错误码,一个强吞异常。
