版权声明:仅供学习。
持续更新中…也算是个人学习的监督与激励吧。
OI路漫漫,且行且珍惜。
OI太颓了,模拟赛都打不动,班级全是大佬。
算法综合
- \(Algorithm\)
杂题综合
Index 1:
While moving to a new compound the Byteotian Institute of Experimental Physics has encountered a logisticalproblem – the transfer of its vast collection of precision weights turned out to be non-trivial.
The Institute has a certain number of containers of limited strength at its disposal. As many weightsas possible are to be put into the containers, the remaining ones will be discarded. There is no limit onthe number of weights to be put in a container apart from the requirement of not exceeding its strength. Acontainer may also be empty.
Any two weights in the Institute have a peculiar property: the mass of one of them is an integer multipleof the mass of the other. Particularly, they may have the same mass.
TaskWrite a programme which:
reads the durabilities of the containers and masses of the weights from the standard input, determines the maximal number of weights that can be put in the containers, writes the outcome to the standard output.
The first line of the standard input contains two integers \(n\) and \(m\)(\(1\le n,m\le 100\ 000\)), separated by a singlespace, denoting respectively: the number of containers and the number of weights. The second line of thestandard input consists of \(n\) integers \(w_i\) (\(1\le w_i\le 1\ 000\ 000\ 000\) for \(1\le i\le n\)), separated by single spaces,denoting the strengths of containers in milligrammes. In the third line there are \(m\) integers \(m_j\)(\(1\le m_j\le 1\ 000\ 000\ 000\)) for \(1\le j\le m\)), separated by single spaces, denoting masses of the weights in milligrammes.
The first and only line of the standard output should contain a single integer -the maximal number ofweights that can be placed in the containers without exceeding their durability.
Aim 1:题目大意
\(n\) 个容器,\(m\) 个砝码。
求最大能装下多少砝码。
较为特别的砝码的质量两两成倍数关系。
看起来是什么背包,但是。。。
所以我们要抓住砝码的质量两两成倍数关系。
这里显然暗藏玄机,其实很容易可以想到这和进制有关系,毕竟进制的每一位的权值都是倍数关系,如果没有这个砝码只是这一位为 \(0\) 罢了。
Aim 2:砝码进制
此时我们有两个容器质量 13 9
这里有四个砝码 2 4 4 12
我们对容器进行砝码进制转化
\(13=(0,0,1)+1\)
每一位从小到大表示砝码质量,而最后剩下的数将对答案没有贡献。
同理 \(9=(0,2,0)+1\) 。
将两个砝码进制数相加,可得:
\((0,2,1)\)
这样做的原因:我们知道它们成倍数关系,那么如果高位可以放下那么低位可以类似借位的形式向高位要。
剩下的部分一定小于任意砝码,不能被利用。
如果不懂可以多想想,不然您无法理解。
Aim 3:贪心借位
既然这样我们已近处理好了,我们发现无论做大的还是小的,其贡献均一致,那么显然!
先做质量小的。
此时我们做 \(2\) 但是没有,就向下一位借位。
\((2,1,1)\)
用掉一个 \(2\),但是剩一个则对后面没有贡献。
\((0,1,1)\) 贡献 \(1\)
此时遇到两个 \(4\),用掉一个并向后借位,并可装下两个,但是剩余则对后面没有贡献。
\((0,0,0)\) 贡献 \(3\)
此时我们得到了代码,在代码实现上注意借位的问题,即可解决,感谢观看!
代码经过格式化,用餐愉快。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m, cnt;
int a[N], b[N], c[N], d[N], num[N];
void dfs(int step, int now)
{
if (step == cnt + 1)
return;
if (c[step] && step == now)
return;
if (c[step])
{
c[step]--;
c[step - 1] += b[step] / b[step - 1];
return;
}
else
{
dfs(step + 1, now);
if (c[step] && step != now)
c[step]--, c[step - 1] += b[step] / b[step - 1];
}
}
signed main()
{
n = read(), m = read();
for (int i = 1; i <= n; ++i)
a[i] = read();
for (int i = 1; i <= m; ++i)
b[i] = read(), d[i] = b[i];
sort(d + 1, d + m + 1);
cnt = 0;
for (int i = 1; i <= m; ++i)
if (d[i] != d[i - 1])
b[++cnt] = d[i], num[cnt]++;
else
num[cnt]++;
for (int i = 1; i <= n; ++i)
{
for (int j = cnt; j >= 1; --j)
{
c[j] += a[i] / b[j];
a[i] %= b[j];
}
}
for (int i = 1, j = 1; i <= cnt; ++i)
{
while (num[i]--)
{
dfs(i, i);
if (c[i])
c[i]--;
else
{
printf("%d\n", j - 1);
return 0;
}
++j;
}
}
printf("%d\n", m);
return 0;
}
Index 2:
物流公司要把一批货物从码头 A 运到码头 B。由于货物量比较大,需要 \(n\) 天才能运完。货物运输过程中一般要转停好几个码头。
物流公司通常会设计一条固定的运输路线,以便对整个运输过程实施严格的管理和跟踪。由于各种因素的存在,有的时候某个码头会无法装卸货物。这时候就必须修改运输路线,让货物能够按时到达目的地。
但是修改路线是—件十分麻烦的事情,会带来额外的成本。因此物流公司希望能够订一个 \(n\) 天的运输计划,使得总成本尽可能地小。
第一行是四个整数 \(n,m,k,e\)。\(n\) 表示货物运输所需天数,\(m\) 表示码头总数,\(k\) 表示每次修改运输路线所需成本,\(e\) 表示航线条数。
接下来 \(e\) 行每行是一条航线描述,包括了三个整数,依次表示航线连接的两个码头编号以及航线长度。其中码头 A 编号为 \(1\),码头 B 编号为 \(m\)。单位长度的运输费用为 \(1\)。航线是双向的。
再接下来一行是一个整数 \(d\),后面的 \(d\) 行每行是三个整数 \(p,a,b\)。表示编号为 \(p\) 的码头在 \([a,b]\) 天之内无法装卸货物。同一个码头有可能在多个时间段内不可用。但任何时间都存在至少一条从码头 A 到码头 B 的运输路线。
包括了一个整数表示最小的总成本。
总成本为 \(n\) 天运输路线长度之和 \(+ k \times\) 改变运输路线的次数。
【数据范围】
对于 \(100\%\) 的数据,\(1 \le n \le 100\),\(1\le m \le 20\), \(1 \le k \le 500\), \(1 \le e \le 200\)。
预处理出每一段时间内都走同一条路的最短路 \(g[i][j]\)
于是我们可以很简单的得到前 \(i\) 天的最小代价 \(f[i]=f[j-1]+g[j][i]*(i-j+1)+k\)
于是这道题目就很巧妙的转换成DP。
即使我没想出来。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e2 + 50;
const int M = 1e3 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m, k, mm, d;
struct edge
{
int to, dis, nxt;
} e[M];
int head[N], cnt;
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
bool a[N][N];
bool b[N];
struct node
{
int pos;
int dis;
bool operator<(const node &x) const
{
return x.dis < dis;
}
};
priority_queue<node> q;
int dis[N];
bool vis[N];
void dij()
{
memset(dis, 0x3f3f3f3f, sizeof(dis));
memset(vis, 0, sizeof(vis));
dis[1] = 0;
q.push((node){1, 0});
while (!q.empty())
{
node tmp = q.top();
q.pop();
int x = tmp.pos;
if (vis[x])
continue;
vis[x] = 1;
for (int i = head[x]; i; i = e[i].nxt)
{
int y = e[i].to;
if (b[y])
continue;
if (dis[y] > dis[x] + e[i].dis)
{
dis[y] = dis[x] + e[i].dis;
q.push((node){y, dis[y]});
}
}
}
}
int f[N], g[N][N];
signed main()
{
n = read(), m = read(), k = read(), mm = read();
for (int i = 1; i <= mm; ++i)
{
int u = read(), v = read(), w = read();
add_edge(u, v, w);
add_edge(v, u, w);
}
d = read();
for (int i = 1; i <= d; ++i)
{
int x = read(), u = read(), v = read();
for (int j = u; j <= v; ++j)
{
a[x][j] = 1;
}
}
for (int i = 1; i <= n; ++i)
{
for (int j = i; j <= n; ++j)
{
memset(b, 0, sizeof(b));
for (int u = i; u <= j; ++u)
{
for (int v = 1; v <= m; ++v)
{
if (a[v][u])
b[v] = 1;
}
}
dij();
g[i][j] = (dis[m] == 0x3f3f3f3f ? -1 : dis[m]);
}
}
memset(f, 0x3f3f3f3f, sizeof(f));
f[0] = 0;
for (int i = 1; i <= n; ++i)
{
if (g[1][i] != -1)
f[i] = g[1][i] * i;
for (int j = i; j >= 1; --j)
{
if (g[j][i] == -1)
continue;
f[i] = min(f[i], f[j - 1] + g[j][i] * (i - j + 1) + k);
}
}
printf("%d\n", f[n]);
return 0;
}
Index 3:
共有 \(4\) 种硬币。面值分别为 \(c_1,c_2,c_3,c_4\)。
某人去商店买东西,去了 \(n\) 次,对于每次购买,他带了 \(d_i\) 枚 \(i\) 种硬币,想购买 \(s\) 的价值的东西。请问每次有多少种付款方法。
输入的第一行是五个整数,分别代表 \(c_1,c_2,c_3,c_4, n\)。
接下来 \(n\) 行,每行有五个整数,描述一次购买,分别代表 \(d_1, d_2, d_3, d_4,s\)。
对于每次购买,输出一行一个整数代表答案。
- 对于 \(100\%\) 的数据,保证 \(1 \leq c_i, d_i, s \leq 10^5\),\(1 \leq n \leq 1000\)。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int c[5], n;
int d[5], s;
int f[N];
int g(int i) { return (d[i] + 1) * c[i]; }
signed main()
{
f[0] = 1;
for (int i = 1; i <= 4; ++i)
{
c[i] = read();
for (int j = c[i]; j <= N - 50; ++j)
{
f[j] += f[j - c[i]];
}
}
n = read();
while (n--)
{
for (int i = 1; i <= 4; ++i)
d[i] = read();
s = read();
int ans = f[s];
if (s >= g(1))
ans -= f[s - g(1)];
if (s >= g(2))
ans -= f[s - g(2)];
if (s >= g(3))
ans -= f[s - g(3)];
if (s >= g(4))
ans -= f[s - g(4)];
if (s >= g(1) + g(2))
ans += f[s - g(1) - g(2)];
if (s >= g(1) + g(3))
ans += f[s - g(1) - g(3)];
if (s >= g(1) + g(4))
ans += f[s - g(1) - g(4)];
if (s >= g(2) + g(3))
ans += f[s - g(2) - g(3)];
if (s >= g(2) + g(4))
ans += f[s - g(2) - g(4)];
if (s >= g(3) + g(4))
ans += f[s - g(3) - g(4)];
if (s >= g(1) + g(2) + g(3))
ans -= f[s - g(1) - g(2) - g(3)];
if (s >= g(1) + g(2) + g(4))
ans -= f[s - g(1) - g(2) - g(4)];
if (s >= g(1) + g(3) + g(4))
ans -= f[s - g(1) - g(3) - g(4)];
if (s >= g(2) + g(3) + g(4))
ans -= f[s - g(2) - g(3) - g(4)];
if (s >= g(1) + g(2) + g(3) + g(4))
ans += f[s - g(1) - g(2) - g(3) - g(4)];
printf("%lld\n", ans);
}
return 0;
}
Index 4:
从文件中读入一个正整数 \(n(10≤n≤31000)\)。要求将n写成若干个正整数之和,并且使这些正整数的乘积最大。
例如,\(n=13\),则当 \(n\) 表示为\(4+3+3+3(或2+2+3+3+3)\)时,乘积 \(108\) 为最大。
只有一个正整数:\(n(10≤n≤31000)\)
第 \(1\) 行输出一个整数,为最大乘积的位数。
第 \(2\) 行输出最大乘积的前 \(100\) 位,如果不足 \(100\) 位,则按实际位数输出最大乘积。
(提示:在给定的范围内,最大乘积的位数不超过 \(5000\) 位)。
结论题,练习高精度可用
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
int x[N];
int a[N];
int cnt = 0;
void dfs(int n)
{
while (n > 4)
{
n -= 3;
x[++cnt] = 3;
}
x[++cnt] = n;
}
int len;
void mul(int m)
{
int tmp = len, k = 0;
for (int i = 1; i <= tmp || k != 0; ++i)
{
len = max(len, i);
if (i <= tmp)
a[i] *= m;
a[i] += k;
k = a[i] / 10;
a[i] %= 10;
}
}
int main()
{
n = read();
dfs(n);
a[1] = 1;
++len;
for (int i = 1; i <= cnt; ++i)
{
mul(x[i]);
}
printf("%d\n", len);
for (int i = len; i >= max(len - 100 + 1, 1); --i)
{
printf("%d", a[i]);
}
printf("\n");
return 0;
}
Index 5:
写一个程序来模拟操作系统的进程调度。假设该系统只有一个 CPU,每一个进程的到达时间,执行时间和运行优先级都是已知的。其中运行优先级用自然数表示,数字越大,则优先级越高。
如果一个进程到达的时候 CPU 是空闲的,则它会一直占用 CPU 直到该进程结束。除非在这个过程中,有一个比它优先级高的进程要运行。在这种情况下,这个新的(优先级更高的)进程会占用 CPU,而老的只有等待。
如果一个进程到达时,CPU 正在处理一个比它优先级高或优先级相同的进程,则这个(新到达的)进程必须等待。
一旦 CPU 空闲,如果此时有进程在等待,则选择优先级最高的先运行。如果有多个优先级最高的进程,则选择到达时间最早的。
输入包含若干行,每一行有四个自然数(均不超过 \(10^8\)),分别是进程号,到达时间,执行时间和优先级。不同进程有不同的编号,不会有两个相同优先级的进程同时到达。输入数据已经按到达时间从小到大排序。输入数据保证在任何时候,等待队列中的进程不超过 \(15000\) 个。
按照进程结束的时间输出每个进程的进程号和结束时间。
模拟题+堆优化
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
struct que
{
int id, fir, len, vol;
bool operator<(const que &o) const
{
if (o.vol != vol)
return o.vol > vol;
else
return o.fir < fir;
}
} a;
priority_queue<que> q;
signed main()
{
int now = 0;
while (scanf("%lld", &a.id) != EOF)
{
scanf("%lld%lld%lld", &a.fir, &a.len, &a.vol);
while (!q.empty() && (now + q.top().len <= a.fir))
{
now += q.top().len;
printf("%lld %lld\n", q.top().id, now);
q.pop();
}
if (!q.empty())
{
que tmp = q.top();
q.pop();
tmp.len -= a.fir - now;
q.push(tmp);
}
q.push(a);
now = a.fir;
}
while (!q.empty())
{
que tmp = q.top();
q.pop();
now += tmp.len;
printf("%lld %lld\n", tmp.id, now);
}
return 0;
}
Index 6:
John 在他的农场中闲逛时发现了许多虫洞。虫洞可以看作一条十分奇特的有向边,并可以使你返回到过去的一个时刻(相对你进入虫洞之前)。
John 的每个农场有 \(m\) 条小路(无向边)连接着 \(n\) 块地(从 \(1 \sim n\) 标号),并有 \(w\) 个虫洞。
现在 John 希望能够从某块地出发,走过一条路径回到出发点,且同时也回到了出发时刻以前的某一时刻。请你告诉他能否做到。
输入的第一行是一个整数 \(T\),代表测试数据的组数。
每组测试数据的格式如下:
每组数据的第一行是三个用空格隔开的整数,分别代表农田的个数 \(n\),小路的条数 \(m\),以及虫洞的个数 \(w\)。
每组数据的第 \(2\) 到第 \((m + 1)\) 行,每行有三个用空格隔开的整数 \(u, v, p\),代表有一条连接 \(u\) 与 \(v\) 的小路,经过这条路需要花费 \(p\) 的时间。
每组数据的第 \((m + 2)\) 到第 \((m + w + 1)\) 行,每行三个用空格隔开的整数 \(u, v, p\),代表点 \(u\) 存在一个虫洞,经过这个虫洞会到达点 \(v\),并回到 \(p\) 秒之前。
对于每组测试数据,输出一行一个字符串,如果能回到出发时刻之前,则输出 YES,否则输出 NO。
对于 \(100\%\) 的数据,\(1 \le T \le 5\),\(1 \le n \le 500\),\(1 \le m \le 2500\),\(1 \le w \le 200\),\(1 \le p \le 10^4\)。
SPFA 判负环经典题目
原理就是进队次数
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int t, n, m, k;
struct edge
{
int to, dis, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int res[N], dis[N];
bool vis[N];
queue<int> q;
bool spfa()
{
for (int i = 1; i <= n; ++i)
{
q.push(i);
vis[i] = 1;
}
while (!q.empty())
{
int u = q.front();
q.pop();
vis[u] = 0;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (dis[v] > dis[u] + e[i].dis)
{
dis[v] = dis[u] + e[i].dis;
res[v] = res[u] + 1;
if (res[v] >= n)
return 1;
if (!vis[v])
{
q.push(v);
vis[v] = 1;
}
}
}
}
return 0;
}
int main()
{
t = read();
while (t--)
{
n = read(), m = read(), k = read();
memset(head, 0, sizeof(head));
memset(dis, 0x3f3f3f3f, sizeof(dis));
memset(res, 0, sizeof(res));
cnt = 0;
for (int i = 1; i <= m; ++i)
{
int u = read(), v = read(), w = read();
add_edge(u, v, w);
add_edge(v, u, w);
}
for (int i = 1; i <= k; ++i)
{
int u = read(), v = read(), w = -read();
add_edge(u, v, w);
}
if (spfa())
{
puts("YES");
}
else
{
puts("NO");
}
}
return 0;
}
动态规划
- \(Dynamic~Programing\)
开坑原因: 模拟赛被DP搞怕了。
况且本身DP就很颓,所以板刷DP。
绝不放弃任何一道DP!————RVG
DP综合
Index 1:
教主有着一个环形的花园,他想在花园周围均匀地种上n棵树,但是教主花园的土壤很特别,每个位置适合种的树都不一样,一些树可能会因为不适合这个位置的土壤而损失观赏价值。
教主最喜欢\(3\)种树,这3种树的高度分别为\(10,20,30\)。教主希望这一圈树种得有层次感,所以任何一个位置的树要比它相邻的两棵树的高度都高或者都低,并且在此条件下,教主想要你设计出一套方案,使得观赏价值之和最高。
第一行为一个正整数\(n\),表示需要种的树的棵树。
接下来\(n\)行,每行\(3\)个不超过\(10000\)的正整数\(a_i,b_i,c_i\),按顺时针顺序表示了第\(i\)个位置种高度为\(10,20,30\)的树能获得的观赏价值。
第\(i\)个位置的树与第\(i+1\)个位置的树相邻,特别地,第\(1\)个位置的树与第\(n\)个位置的树相邻。
一个正整数,为最大的观赏价值和。
对于\(100\%\)的数据,有\(4≤n≤100000\),并保证\(n\)一定为偶数。
Aim 1:动态转移
\]
注意因为是环形的所以,枚举第1棵树满足的取最大。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
int a[N][3];
int f[N][3][2];
int main()
{
n = read();
for (int i = 1; i <= n; ++i)
a[i][0] = read(), a[i][1] = read(), a[i][2] = read();
int ans = 0;
for (int j = 0; j < 3; ++j)
{
memset(f, 0, sizeof(f));
f[1][j][0] = f[1][j][1] = a[1][j];
for (int i = 2; i <= n; ++i)
{
f[i][0][0] = max(f[i - 1][1][1], f[i - 1][2][1]) + a[i][0];
f[i][1][0] = f[i - 1][2][1] + a[i][1];
f[i][1][1] = f[i - 1][0][0] + a[i][1];
f[i][2][1] = max(f[i - 1][1][0], f[i - 1][0][0]) + a[i][2];
}
for (int i = 0; i < j; ++i)
ans = max(ans, f[n][i][0]);
for (int i = 2; i > j; --i)
ans = max(ans, f[n][i][1]);
}
printf("%d\n", ans);
return 0;
}
Index 2:
卡门――农夫约翰极其珍视的一条 Holsteins 奶牛――已经落了到 “垃圾井” 中。“垃圾井” 是农夫们扔垃圾的地方,它的深度为 \(D\)(\(2 \le D \le 100\))英尺。
卡门想把垃圾堆起来,等到堆得高度大等于于井的深度时,她就能逃出井外了。另外,卡门可以通过吃一些垃圾来维持自己的生命。
每个垃圾都可以用来吃或堆放,并且堆放垃圾不用花费卡门的时间。
假设卡门预先知道了每个垃圾扔下的时间 \(t\)(\(1 \le t \le 1000\)),以及每个垃圾堆放的高度 \(h\)(\(1 \le h \le 25\))和吃进该垃圾能维持生命的时间 \(f\)(\(1 \le f \le 30\)),要求出卡门最早能逃出井外的时间,假设卡门当前体内有足够持续 \(10\) 小时的能量,如果卡门 \(10\) 小时内(不含 \(10\) 小时,维持生命的时间同)没有进食,卡门就将饿死。
第一行为两个整数,\(D\) 和 \(G\)(\(1 \le G \le 100\)),\(G\) 为被投入井的垃圾的数量。
第二到第 \(G+1\) 行每行包括三个整数:\(T\)(\(1 \le T \le 1000\)),表示垃圾被投进井中的时间;\(F\)(\(1 \le F \le 30\)),表示该垃圾能维持卡门生命的时间;和 \(H\)(\(1 \le H \le 25\)),该垃圾能垫高的高度。
如果卡门可以爬出陷阱,输出一个整数,表示最早什么时候可以爬出;否则输出卡门最长可以存活多长时间。
Aim 1:动态转移
\]
f_{i-1,j-a_{i.h}} & \text{ if } j \ge a_{i.h} \&\& f_{i-1,j-a_{i.h}} \ge a_{i.t} \\
f_{i-1,j}+a_{i.f} & \text{ if } f_{i-1,j}\ge a_{i.t}
\end{cases}\]
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e2 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
struct node
{
int t, f, h;
} a[N];
bool cmp(node x, node y)
{
return x.t < y.t;
}
int f[N][N];
int main()
{
m = read(), n = read();
int alive = 10;
for (int i = 1; i <= n; ++i)
{
a[i].t = read();
a[i].f = read();
a[i].h = read();
}
sort(a + 1, a + n + 1, cmp);
memset(f, -0x3f, sizeof(f));
f[0][0] = 10;
for (int i = 1; i <= n; ++i)
{
for (int j = 0; j <= m; ++j)
{
if (f[i - 1][j] >= a[i].t)
f[i][j] = max(f[i][j], f[i - 1][j] + a[i].f);
if (j >= a[i].h && f[i - 1][j - a[i].h] >= a[i].t)
f[i][j] = max(f[i][j], f[i - 1][j - a[i].h]);
}
}
bool flag = 0;
for (int i = 1; i <= n; ++i)
{
for (int j = 0; j <= m; ++j)
{
if (f[i][j] >= a[i].t)
{
if (j == m)
{
printf("%d\n", a[i].t);
flag = 1;
break;
}
}
}
alive = max(alive, f[i][0]);
if (flag)
break;
}
if (!flag)
{
printf("%d\n", alive);
}
return 0;
}
Index 3:
一年一度的展会要来临了,Farmer John 想要把 \(N\)(\(1 \leq N \leq 100,000\))只奶牛和公牛安排在单独的一行中。 John 发现最近公牛们非常好斗;假如两只公牛在这一行中靠的太近,他们就会吵架,以至于斗殴,破坏这和谐的环境。
John 非常的足智多谋,他计算出任何两只公牛之间至少要有 \(K\)(\(0 \leq K \lt N\))只奶牛,这样才能避免斗殴。John 希望你帮助他计算一下有多少种安排方法,可避免任何斗殴的的发生。John 认为每头公牛都是一样的,每头奶牛都是一样的。因而,只要在一些相同的位置上有不同种类的牛,那这就算两种不同的方法。
两个整数 \(N\) 和 \(K\)。
输出约翰可以安排的方法数。考虑到这个数可能很大,你只要输出对 \(5\,000\,011\) 取模之后的结果就可以了。
Aim 1:动态转移
\(fg_i\) 表示当前位置放公牛的方案数
\(fn_i\) 表示当前位置放奶牛的方案数
\]
1 & \text{ if } i\leq k+1 \\
fg_{i-k-1}+fn_{i-k-1} & \text{ if } i > k+1
\end{cases}\]
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 5000011;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, k;
int fn[N], fg[N];
signed main()
{
n = read(), k = read();
fn[1] = fg[1] = 1;
for (int i = 2; i <= n; ++i)
{
fn[i] = fn[i - 1] + fg[i - 1];
fn[i] %= Mod;
if (i > k + 1)
fg[i] = fn[i - k - 1] + fg[i - k - 1];
else
fg[i] = 1;
fg[i] %= Mod;
}
printf("%lld\n", (fn[n] + fg[n]) % Mod);
return 0;
}
Index 4:
某人有一套玩具,并想法给玩具命名。首先他选择WING四个字母中的任意一个字母作为玩具的基本名字。然后他会根据自己的喜好,将名字中任意一个字母用“WING”中任意两个字母代替,使得自己的名字能够扩充得很长。
现在,他想请你猜猜某一个很长的名字,最初可能是由哪几个字母变形过来的。
第一行四个整数W、I、N、G。表示每一个字母能由几种两个字母所替代。
接下来W行,每行两个字母,表示W可以用这两个字母替代。
接下来I行,每行两个字母,表示I可以用这两个字母替代。
接下来N行,每行两个字母,表示N可以用这两个字母替代。
接下来G行,每行两个字母,表示G可以用这两个字母替代。
最后一行一个长度不超过Len的字符串。表示这个玩具的名字。
一行字符串,该名字可能由哪些字母变形而得到。(按照WING的顺序输出)
如果给的名字不能由任何一个字母变形而得到则输出“The name is wrong!”
\(30\%\)数据满足\(Len<=20,W、I、N、G<=6\)
\(100\%\)数据满足\(Len<=200,W、I、N、G<=16\)
\(a_{i,j,k}\) 表示 \(i\) 可以用 \(j,k\) 表示
\(f_{i,j,k}\) 表示 子段 \(i\sim j\) 是 \(k\) 转换的
根据这个思路区间DP即可。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
bool a[5][5][5];
bool f[250][250][5];
char opt[2];
int to(char x)
{
if (x == 'W')
return 1;
if (x == 'I')
return 2;
if (x == 'N')
return 3;
if (x == 'G')
return 4;
}
string s;
int m[5];
int main()
{
m[1] = read(), m[2] = read(), m[3] = read(), m[4] = read();
for (int i = 1; i <= 4; ++i)
{
for (int j = 1; j <= m[i]; ++j)
{
scanf("%s", opt);
a[i][to(opt[0])][to(opt[1])] = 1;
}
}
cin >> s;
n = s.size();
for (int i = 0; i < n; ++i)
{
f[i][i][to(s[i])] = 1;
}
for (int len = 2; len <= n; ++len)
{
for (int l = 0; l < n - len + 1; ++l)
{
int r = l + len - 1;
for (int k = l; k < r; ++k)
{
for (int u = 1; u <= 4; ++u)
{
for (int v = 1; v <= 4; ++v)
{
for (int w = 1; w <= 4; ++w)
{
if (a[u][v][w] && f[l][k][v] && f[k + 1][r][w])
f[l][r][u] = 1;
}
}
}
}
}
}
bool flag = 1;
if (f[0][n - 1][1])
printf("W"), flag = 0;
if (f[0][n - 1][2])
printf("I"), flag = 0;
if (f[0][n - 1][3])
printf("N"), flag = 0;
if (f[0][n - 1][4])
printf("G"), flag = 0;
if (flag)
{
printf("The name is wrong!");
}
return 0;
}
Index 5:
windy学会了一种游戏。
对于1到N这N个数字,都有唯一且不同的1到N的数字与之对应。
最开始windy把数字按顺序1,2,3,……,N写一排在纸上。
然后再在这一排下面写上它们对应的数字。
然后又在新的一排下面写上它们对应的数字。
如此反复,直到序列再次变为1,2,3,……,N。
如:
1 2 3 4 5 6
对应的关系为
1->2 2->3 3->1 4->5 5->4 6->6
windy的操作如下
1 2 3 4 5 6
2 3 1 5 4 6
3 1 2 4 5 6
1 2 3 5 4 6
2 3 1 4 5 6
3 1 2 5 4 6
1 2 3 4 5 6
这时,我们就有若干排1到N的排列,上例中有7排。
现在windy想知道,对于所有可能的对应关系,有多少种可能的排数。
一个整数,N。
一个整数,可能的排数。
\(30\%\)的数据,满足 \(1 <= N <= 10\) 。
\(100\%\)的数据,满足 \(1 <= N <= 1000\) 。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int prime[N], cnt;
int phi[N];
bool is_prime[N];
void pre(int k)
{
memset(is_prime, 1, sizeof(is_prime));
is_prime[1] = 0;
phi[1] = 1;
for (int i = 2; i <= k; ++i)
{
if (is_prime[i])
{
prime[++cnt] = i;
phi[i] = i - 1;
}
for (int j = 1; j <= cnt && i * prime[j] <= k; ++j)
{
is_prime[i * prime[j]] = 0;
if (i % prime[j])
{
phi[i * prime[j]] = phi[i] * phi[prime[j]];
}
else
{
phi[i * prime[j]] = phi[i] * prime[j];
}
}
}
}
int n;
int f[N];
signed main()
{
n = read();
pre(n);
f[0] = 1;
for (int i = 1; i <= cnt; ++i)
{
for (int j = n; j >= prime[i]; --j)
{
int k = prime[i];
while (k <= j)
{
f[j] += f[j - k];
k *= prime[i];
}
}
}
int ans = 0;
for (int i = 0; i <= n; ++i)
ans += f[i];
printf("%lld\n", ans);
return 0;
}
Index 6:
折叠的定义如下:
-
一个字符串可以看成它自身的折叠。记作
S = S -
X(S)是 \(X\) 个S连接在一起的串的折叠。记作X(S) = SSSS…S。 -
如果
A = A’,B = B’,则AB = A’B’。例如:因为3(A) = AAA,2(B) = BB,所以3(A)C2(B) = AAACBB,而2(3(A)C)2(B) = AAACAAACBB
给一个字符串,求它的最短折叠。
例如 AAAAAAAAAABABABCCD 的最短折叠为:9(A)3(AB)CCD。
仅一行,即字符串 S,长度保证不超过 \(100\)。
仅一行,即最短的折叠长度。
正常区间DP很容易理解
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e2 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
char s[N];
int f[N][N], a[N];
bool check(int l, int r, int len)
{
for (int i = l; i <= r; ++i)
{
if (s[i] != s[(i - l) % len + l])
return false;
}
return true;
}
int main()
{
scanf("%s", s + 1);
n = strlen(s + 1);
for (int i = 1; i <= 9; ++i)
a[i] = 1;
for (int i = 10; i <= 99; ++i)
a[i] = 2;
a[100] = 3;
memset(f, 0x3f3f3f3f, sizeof(f));
for (int i = 1; i <= n; ++i)
f[i][i] = 1;
for (int len = 2; len <= n; ++len)
{
for (int l = 1; l <= n - len + 1; ++l)
{
int r = l + len - 1;
for (int k = l; k < r; ++k)
{
f[l][r] = min(f[l][k] + f[k + 1][r], f[l][r]);
}
for (int k = l; k < r; ++k)
{
int o = k - l + 1;
if (len % o)
continue;
if (check(l, r, o))
f[l][r] = min(f[l][k] + 2 + a[len / o], f[l][r]);
}
}
}
printf("%d\n", f[1][n]);
return 0;
}
Index 7:
Farmer John 的 \(N(1 \le N \le 500)\) 头奶牛打算参加一场世界级的产奶比赛 (Multistate Milking Match-up,MMM),他们已经摸清了其他队的实力。他们的总产奶量只要大于等于 \(X\) 加仑(\(1 \leq X \leq 10^6\)),就能赢得胜利。
每头奶牛都能为全队贡献一定量的牛奶,数值在 \(-10^4\) 到 \(10^4\) 加仑之间(为啥有负数?因为有些奶牛会打翻其他奶牛产的牛奶)。
MMM 的目标是通过合作,增进家庭成员间的默契。为了支持比赛精神,奶牛们希望在赢得比赛的前提下,有尽可能多对奶牛间存在直系血缘关系。当然,所有奶牛都是女性,因此这里的直系血缘关系就是母女关系。
现在 FJ 摸清了所有奶牛间的血缘关系,希望算出一个团队在赢得胜利的前提下,最多有多少对奶牛存在血缘关系。注意:如果一个团队由某头奶牛和她的母亲和外祖母组成的话,这个团队只有两对血缘关系(她和她的母亲,她的母亲和外祖母)。
第一行两个整数 \(N,X\)。
接下来 \(N\) 行,每行两个整数,第一个整数是它能为团队贡献的产奶量,第二个整数为它的母亲的编号,如果她的母亲不在牛群里,这个数字为 \(0\)。
保证血缘关系不会出现环。
输出在获胜的前提下,一个团队中最多存在多少血缘关系。
特别地,如果不存在一个团队能获胜,输出 \(-1\)。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 5e2 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, x;
vector<int> tree[N];
int a[N];
int f[N][N][2];
void dfs(int u)
{
f[u][0][0] = 0, f[u][0][1] = a[u];
for (int i = 0; i < tree[u].size(); ++i)
{
int v = tree[u][i];
dfs(v);
for (int j = n - 1; j >= 0; --j)
{
for (int k = j; k >= 0; --k)
f[u][j][0] = max(f[u][j][0], f[u][k][0] + max(f[v][j - k][0], f[v][j - k][1]));
for (int k = j; k >= 0; --k)
f[u][j][1] = max(f[u][j][1], f[u][k][1] + f[v][j - k][0]);
for (int k = j - 1; k >= 0; --k)
f[u][j][1] = max(f[u][j][1], f[u][k][1] + f[v][j - k - 1][1]);
}
}
}
int main()
{
memset(f, -0x3f3f, sizeof(f));
n = read(), x = read();
for (int i = 1; i <= n; ++i)
{
a[i] = read();
tree[read()].push_back(i);
}
dfs(0);
for (int i = n - 1; i >= 0; --i)
{
if (f[0][i][0] >= x)
{
printf("%d\n", i);
return 0;
}
}
puts("-1");
return 0;
}
Index 8:
某收费有线电视网计划转播一场重要的足球比赛。他们的转播网和用户终端构成一棵树状结构,这棵树的根结点位于足球比赛的现场,树叶为各个用户终端,其他中转站为该树的内部节点。
从转播站到转播站以及从转播站到所有用户终端的信号传输费用都是已知的,一场转播的总费用等于传输信号的费用总和。
现在每个用户都准备了一笔费用想观看这场精彩的足球比赛,有线电视网有权决定给哪些用户提供信号而不给哪些用户提供信号。
写一个程序找出一个方案使得有线电视网在不亏本的情况下使观看转播的用户尽可能多。
输入文件的第一行包含两个用空格隔开的整数 \(N\) 和 \(M\),其中 \(2 \le N \le 3000\),\(1 \le M \le N-1\),\(N\) 为整个有线电视网的结点总数,\(M\) 为用户终端的数量。
第一个转播站即树的根结点编号为 \(1\),其他的转播站编号为 \(2\) 到 \(N-M\),用户终端编号为 \(N-M+1\) 到 \(N\)。
接下来的 \(N-M\) 行每行表示—个转播站的数据,第 \(i+1\) 行表示第 \(i\) 个转播站的数据,其格式如下:
\(K \ \ A_1 \ \ C_1 \ \ A_2 \ \ C_2 \ \ \ldots \ \ A_k \ \ C_k\)
\(K\) 表示该转播站下接 \(K\) 个结点(转播站或用户),每个结点对应一对整数 \(A\) 与 \(C\) ,\(A\) 表示结点编号,\(C\) 表示从当前转播站传输信号到结点 \(A\) 的费用。最后一行依次表示所有用户为观看比赛而准备支付的钱数。单次传输成本和用户愿意交的费用均不超过 10。
输出文件仅一行,包含一个整数,表示上述问题所要求的最大用户数。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 3e3 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
struct edge
{
int to, dis, nxt;
} e[N << 1];
int head[N], cnt;
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int f[N][N], w[N];
int dfs(int u)
{
if (u > n - m)
{
f[u][1] = w[u];
return 1;
}
int res = 0;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to, w = e[i].dis;
int q = dfs(v);
res += q;
for (int j = res; j >= 1; --j)
{
for (int k = 1; k <= q; ++k)
{
if (j - k >= 0)
f[u][j] = max(f[u][j], f[u][j - k] + f[v][k] - w);
}
}
}
return res;
}
int main()
{
memset(f, -0x3f3f3f, sizeof(f));
n = read(), m = read();
for (int i = 1; i <= n - m; ++i)
{
int k = read();
for (int j = 1; j <= k; ++j)
{
int v = read(), w = read();
add_edge(i, v, w);
}
}
for (int i = n - m + 1; i <= n; ++i)
w[i] = read();
for (int i = 1; i <= n; ++i)
f[i][0] = 0;
dfs(1);
for (int i = m; i >= 1; --i)
if (f[1][i] >= 0)
{
printf("%d\n", i);
break;
}
return 0;
}
Index 9:
设有字符串 \(X\),我们称在 \(X\) 的头尾及中间插入任意多个空格后构成的新字符串为 \(X\) 的扩展串,如字符串 \(X\) 为abcbcd,则字符串abcb□cd,□a□bcbcd□和abcb□cd□ 都是 \(X\) 的扩展串,这里□代表空格字符。
如果 \(A_1\) 是字符串 \(A\) 的扩展串,\(B_1\) 是字符串 \(B\) 的扩展串,\(A_1\) 与 \(B_1\) 具有相同的长度,那么我们定义字符串 \(A_1\) 与 \(B_1\) 的距离为相应位置上的字符的距离总和,而两个非空格字符的距离定义为它们的 ASCII 码的差的绝对值,而空格字符与其他任意字符之间的距离为已知的定值K,空格字符与空格字符的距离为 \(0\)。在字符串 \(A\)、\(B\) 的所有扩展串中,必定存在两个等长的扩展串 \(A_1\),\(B_1\),使得 \(A_1\) 与 \(B_1\) 之间的距离达到最小,我们将这一距离定义为字符串 \(A\),\(B\) 的距离。
请你写一个程序,求出字符串 \(A\),\(B\) 的距离。
输入文件第一行为字符串 \(A\) ,第二行为字符串 \(B\)。\(A\),\(B\) 均由小写字母组成且长度均不超过 \(2000\)。第三行为一个整数 \(K(1\leq K\leq 100)\),表示空格与其他字符的距离。
输出文件仅一行包含一个整数,表示所求得字符串 \(A,B\) 的距离。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 2e3 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
char a[N], b[N];
int n, m, k;
int f[N][N];
int main()
{
memset(f, 0x3f3f3f3f, sizeof(f));
scanf("%s%s", a + 1, b + 1);
k = read();
n = strlen(a + 1), m = strlen(b + 1);
f[0][0] = 0;
for (int i = 0; i <= n; ++i)
{
for (int j = 0; j <= m; ++j)
{
f[i][j] = min(f[i][j], min(i > 0 ? f[i - 1][j] + k : 0x3f3f3f3f, min(j > 0 ? f[i][j - 1] + k : 0x3f3f3f3f, i > 0 && j > 0 ? f[i - 1][j - 1] + abs(a[i] - b[j]) : 0x3f3f3f3f)));
}
}
printf("%d\n", f[n][m]);
return 0;
}
Index 10:
给你一个长度为 \(n(1 \le n \le 500)\) 的数组 \(a\),每次你可以进行以下两步操作:
-
找到 \(i \in [1, n)\),使得 \(a_i = a_{i + 1}\);
-
将 它们 替换为 \(a_i + 1\)。
每轮操作之后,显然数组的长度会减小 \(1\),问剩余数组长度的最小值。
第一行包含一个整数 \(n(1 \le n \le 500)\),表示数组的原长。
第二行包含 \(n\) 个整数 \(a_1, a_2, \cdots a_n (1 \le a_i \le 1000)\),表示原数组 \(a\)。
共一行仅一个整数 \(num\),表示进行许多轮操作之后,\(a\) 剩余长度的最小值。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 5e2 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
int a[N];
int f[N][N], g[N][N];
int main()
{
memset(f, 0x3f3f3f3f, sizeof(f));
n = read();
for (int i = 1; i <= n; ++i)
a[i] = read();
for (int i = 1; i <= n; ++i)
f[i][i] = 1, g[i][i] = a[i];
for (int len = 1; len <= n; ++len)
{
for (int l = 1; l <= n - len + 1; ++l)
{
int r = l + len - 1;
for (int k = l; k < r; ++k)
{
f[l][r] = min(f[l][r], f[l][k] + f[k + 1][r]);
if (g[l][k] == g[k + 1][r] && f[l][k] == 1 && f[k + 1][r] == 1)
{
f[l][r] = 1, g[l][r] = g[l][k] + 1;
}
}
}
}
printf("%d\n", f[1][n]);
return 0;
}
状压DP
Index 1:
农场主 \(\rm John\) 新买了一块长方形的新牧场,这块牧场被划分成 \(M\) 行 \(N\) 列 \((1 \le M \le 12; 1 \le N \le 12)\),每一格都是一块正方形的土地。 \(\rm John\) 打算在牧场上的某几格里种上美味的草,供他的奶牛们享用。
遗憾的是,有些土地相当贫瘠,不能用来种草。并且,奶牛们喜欢独占一块草地的感觉,于是 \(\rm John\) 不会选择两块相邻的土地,也就是说,没有哪两块草地有公共边。
\(\rm John\) 想知道,如果不考虑草地的总块数,那么,一共有多少种种植方案可供他选择?(当然,把新牧场完全荒废也是一种方案)
第一行:两个整数 \(M\) 和 \(N\),用空格隔开。
第 \(2\) 到第 \(M+1\) 行:每行包含 \(N\) 个用空格隔开的整数,描述了每块土地的状态。第 \(i+1\) 行描述了第 \(i\) 行的土地,所有整数均为 \(0\) 或 \(1\) ,是 \(1\) 的话,表示这块土地足够肥沃,\(0\) 则表示这块土地不适合种草。
一个整数,即牧场分配总方案数除以 \(100,000,000\) 的余数。
经典状压
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 20;
const int M = 5e3 + 50;
const int Mod = 1e8;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N];
vector<int> st;
void init()
{
for (int i = 0; i < (1 << m); ++i)
{
if (!(i & (i << 1)))
st.push_back(i);
}
}
int f[N][M];
int main()
{
n = read(), m = read();
init();
for (int i = 1; i <= n; ++i)
{
for (int j = 1; j <= m; ++j)
{
a[i] = (a[i] << 1) + read();
}
}
f[0][0] = 1;
for (int i = 1; i <= n; ++i)
{
for (int j = 0; j < st.size(); ++j)
{
if ((st[j] & a[i]) != st[j])
continue;
for (int k = 0; k < st.size(); ++k)
{
if ((st[k] & a[i - 1]) != st[k])
continue;
if ((st[k] & st[j]) != 0)
continue;
f[i][st[j]] = (f[i][st[j]] + f[i - 1][st[k]]) % Mod;
}
}
}
int ans = 0;
for (int i = 0; i < st.size(); ++i)
ans = (ans + f[n][st[i]]) % Mod;
printf("%d\n", ans);
return 0;
}
Index 2:
在N×N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案。国王能攻击到它上下左右,以及左上左下右上右下八个方向上附近的各一个格子,共8个格子。
只有一行,包含两个数N,K ( 1 <=N <=9, 0 <= K <= N * N)
所得的方案数
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 20;
const int M = 2e3 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
vector<int> st;
int cont(int n)
{
int res = 0;
while (n)
{
res += n % 2;
n /= 2;
}
return res;
}
void init()
{
for (int i = 0; i < (1 << n); ++i)
{
if ((i & (i << 1)) != 0)
continue;
st.push_back(i);
}
}
int f[N][M][N];
signed main()
{
n = read(), m = read();
init();
f[0][0][0] = 1;
for (int i = 1; i <= n; ++i)
{
for (int j = 0; j < st.size(); ++j)
{
for (int k = 0; k < st.size(); ++k)
{
for (int u = cont(st[j]); u <= m; ++u)
{
if ((st[j] & st[k]) != 0)
continue;
int res = st[j] | st[k];
if ((res & (res << 1)) != 0)
continue;
f[i][st[j]][u] += f[i - 1][st[k]][u - cont(st[j])];
}
}
}
}
int ans = 0;
for (int i = 0; i < st.size(); ++i)
ans += f[n][st[i]][m];
printf("%lld\n", ans);
return 0;
}
树形结构
- \(Tree\)
简单树上问题
Index 1:
求一棵树的重心,即找一点使其最大子树的节点数最小。
现在给你一棵树,要你求其重心,如果有多个请全部输出。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
struct edge
{
int to, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int siz[N];
int ans[N], res, maxn = 0x3f3f3f3f;
void dfs(int u, int p)
{
siz[u] = 1;
int Max = 0;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p)
continue;
dfs(v, u);
siz[u] += siz[v];
Max = max(Max, siz[v]);
}
Max = max(Max, n - siz[u]);
if (Max < maxn)
{
maxn = Max;
res = 1;
ans[res] = u;
}
else if (Max == maxn)
{
ans[++res] = u;
}
}
int main()
{
n = read();
for (int i = 1; i < n; ++i)
{
int u = read(), v = read();
add_edge(u, v);
add_edge(v, u);
}
dfs(1, 0);
sort(ans + 1, ans + res + 1);
for (int i = 1; i <= res; ++i)
printf("%d ", ans[i]);
return 0;
}
Index 2:
求一棵树的直径,即最远两点的距离。
现在给你一棵树,求它的直径。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
struct edge
{
int to, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int dis[N];
void dfs(int u, int p, int dep)
{
dis[u] = dep;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p)
continue;
dfs(v, u, dep + 1);
}
}
int main()
{
n = read();
for (int i = 1; i < n; ++i)
{
int u = read(), v = read();
add_edge(u, v);
add_edge(v, u);
}
dfs(1, 0, 0);
int Maxn = 0, Maxi;
for (int i = 1; i <= n; ++i)
{
if (dis[i] > Maxn)
{
Maxn = dis[i];
Maxi = i;
}
}
dfs(Maxi, 0, 0);
Maxn = 0;
for (int i = 1; i <= n; ++i)
Maxn = max(Maxn, dis[i]);
printf("%d\n", Maxn);
return 0;
}
树上分治
Index 1:
给你一棵树,要你求其中距离不大于 \(K\) 的点对数。
Aim 1:分治思想
这里的分治属于点分治
分治是分部解决一整个问题,我们考虑它的划分阶段,不难想到应当以子树的重心为划分点,这样我们可以保证它的时间复杂度达到 \(\mathcal{O(nlog_2n)}\) 。
Aim 2:阶段问题
对于每一阶段应当处理的问题。
我们可以先预处理出所有节点除重心外到重心的距离。
将距离数组定义为dis[]
然后我们可以将原问题转化为 \(dis[i]+dis[j]<=K\)。但是需要保证 \(i,j\) 不在一个连通块内。
Q:这应当如何快速解决?
A:利用双指针的思想,先将数组排序,让后不断移动左右指针,累计答案。
Q:但是这么一想不会有重复的计算吗?
A:很好,所以我们应当减去以重心为根的子树的儿子节点的答案。
想必,您根据上书提问已经了解了问题的精髓所在,所以快去练练吧!这里是我的代码。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, k;
struct edge
{
int to, dis, nxt;
} e[N];
int head[N], cnt;
bool vis[N];
int dis[N];
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int res, root, Min;
int siz[N];
void dfs_siz(int u, int p)
{
siz[u] = 1;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p || vis[v])
continue;
dfs_siz(v, u);
siz[u] += siz[v];
}
}
void dfs_root(int u, int p, int s)
{
int Max = s - siz[u];
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p || vis[v])
continue;
Max = max(Max, siz[v]);
dfs_root(v, u, s);
}
if (Max < Min)
{
Min = Max;
root = u;
}
}
void dfs_dis(int u, int p, int d)
{
dis[++res] = d;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p || vis[v])
continue;
dfs_dis(v, u, d + e[i].dis);
}
}
int sol(int u, int d)
{
res = 0;
dfs_dis(u, 0, d);
sort(dis + 1, dis + res + 1);
int tot = 0, L = 1, R = res;
while (L < R)
{
while (L < R && dis[L] + dis[R] > k)
R--;
tot += R - L;
++L;
}
return tot;
}
int ans;
void dfs(int u)
{
Min = 0x3f3f3f3f;
dfs_siz(u, 0);
dfs_root(u, 0, siz[u]);
ans += sol(root, 0);
vis[root] = 1;
for (int i = head[root]; i; i = e[i].nxt)
{
int v = e[i].to;
if (vis[v])
continue;
ans -= sol(v, e[i].dis);
dfs(v);
}
}
void work()
{
memset(head, 0, sizeof(head));
memset(dis, 0, sizeof(dis));
memset(vis, 0, sizeof(vis));
for (int i = 1; i < n; ++i)
{
int u = read(), v = read(), w = read();
add_edge(u, v, w);
add_edge(v, u, w);
}
dfs(1);
printf("%d\n", ans);
ans = cnt = 0;
}
int main()
{
while (1)
{
n = read(), k = read();
if (n == 0 && k == 0)
break;
work();
}
}
图论
默认最基本的模板以及变形您已经掌握,若没有立即退出阅读此章节,学习后阅读。
2022 年的CSP-S,大家也看到了,图论从老师口中的“最多考一题”,结果一跃成为考试的主要考点。所以学习图论的重要性十分重要。
拓扑排序
- \(Toposort\)
概念引入:DAG 有向无环图。
- 算法实现过程
- 选择入度为 \(0\) 的点作为起点。
- 删除该顶点以及以她为顶点的所有有向边。
- 重复以上操作。
- 如果图空结束且无环;否则有环无拓扑排序。
显然对于任意一个 DAG 她的拓扑排序可能不唯一。
Index 1:
给你一个食物网,你要求出这个食物网中最大食物链的数量。
(这里的“最大食物链”,指的是生物学意义上的食物链,即最左端是不会捕食其他生物的生产者,最右端是不会被其他生物捕食的消费者。)
Delia 非常急,所以你只有 \(1\) 秒的时间。
由于这个结果可能过大,你只需要输出总数模上 \(80112002\) 的结果。
第一行,两个正整数 \(n、m\),表示生物种类 \(n\) 和吃与被吃的关系数 \(m\)。
接下来 \(m\) 行,每行两个正整数,表示被吃的生物A和吃A的生物B。
一行一个整数,为最大食物链数量模上 \(80112002\) 的结果。
各测试点满足以下约定:
数据中不会出现环,满足生物学的要求。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 5e3 + 50;
const int M = 1e6 + 50;
const int Mod = 80112002;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
struct edge
{
int to, nxt;
} e[M];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int in[N], out[N];
int f[N];
void topo()
{
queue<int> q;
for (int i = 1; i <= n; ++i)
{
if (in[i])
continue;
q.push(i);
f[i] = 1;
}
while (!q.empty())
{
int u = q.front();
q.pop();
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
in[v]--;
f[v] = (f[v] + f[u]) % Mod;
if (!in[v])
q.push(v);
}
}
}
int main()
{
n = read(), m = read();
for (int i = 1; i <= m; ++i)
{
int u = read(), v = read();
in[v]++, out[u]++;
add_edge(u, v);
}
topo();
int ans = 0;
for (int i = 1; i <= n; ++i)
if (!out[i])
ans = (ans + f[i]) % Mod;
printf("%d\n", ans);
return 0;
}
Index 2:
小明要去一个国家旅游。这个国家有#\(N\)个城市,编号为\(1\)至\(N\),并且有\(M\)条道路连接着,小明准备从其中一个城市出发,并只往东走到城市i停止。
所以他就需要选择最先到达的城市,并制定一条路线以城市i为终点,使得线路上除了第一个城市,每个城市都在路线前一个城市东面,并且满足这个前提下还希望游览的城市尽量多。
现在,你只知道每一条道路所连接的两个城市的相对位置关系,但并不知道所有城市具体的位置。现在对于所有的i,都需要你为小明制定一条路线,并求出以城市\(i\)为终点最多能够游览多少个城市。
第\(1\)行为两个正整数\(N, M\)。
接下来\(M\)行,每行两个正整数\(x, y\),表示了有一条连接城市\(x\)与城市\(y\)的道路,保证了城市\(x\)在城市\(y\)西面。
\(N\)行,第\(i\)行包含一个正整数,表示以第\(i\)个城市为终点最多能游览多少个城市。
对于\(20\%\)的数据,\(N ≤ 100\);
对于\(60\%\)的数据,\(N ≤ 1000\);
对于\(100\%\)的数据,\(N ≤ 100000,M ≤ 200000\)。
发现是个DAG
但凡你有点地理常识。
那么,拓扑走起。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
struct node
{
int to, nxt;
} e[N << 1];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int f[N];
int in[N];
void topo()
{
queue<int> q;
for (int i = 1; i <= n; ++i)
if (!in[i])
q.push(i), f[i] = 1;
while (!q.empty())
{
int u = q.front();
q.pop();
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
--in[v];
f[v] = max(f[v], f[u] + 1);
if (!in[v])
q.push(v);
}
}
}
int main()
{
n = read(), m = read();
for (int i = 1; i <= m; ++i)
{
int u = read(), v = read();
add_edge(u, v);
in[v]++;
}
topo();
for (int i = 1; i <= n; ++i)
{
printf("%d\n", f[i]);
}
return 0;
}
Index 3:
John的农场在给奶牛挤奶前有很多杂务要完成,每一项杂务都需要一定的时间来完成它。比如:他们要将奶牛集合起来,将他们赶进牛棚,为奶牛清洗乳房以及一些其它工作。尽早将所有杂务完成是必要的,因为这样才有更多时间挤出更多的牛奶。当然,有些杂务必须在另一些杂务完成的情况下才能进行。比如:只有将奶牛赶进牛棚才能开始为它清洗乳房,还有在未给奶牛清洗乳房之前不能挤奶。我们把这些工作称为完成本项工作的准备工作。至少有一项杂务不要求有准备工作,这个可以最早着手完成的工作,标记为杂务\(1\)。John有需要完成的\(n\)个杂务的清单,并且这份清单是有一定顺序的,杂务\(k(k>1)\)的准备工作只可能在杂务\(1\)至\(k-1\)中。
写一个程序从\(1\)到\(n\)读入每个杂务的工作说明。计算出所有杂务都被完成的最短时间。当然互相没有关系的杂务可以同时工作,并且,你可以假定John的农场有足够多的工人来同时完成任意多项任务。
第1行:一个整数\(n\),必须完成的杂务的数目(\(3 \le n \le 10,000\));
第\(2\)至\((n+1)\)行: 共有\(n\)行,每行有一些用\(1\)个空格隔开的整数,分别表示:
* 工作序号(\(1\)至\(n\),在输入文件中是有序的);
* 完成工作所需要的时间\(len(1 \le len \le 100)\);
* 一些必须完成的准备工作,总数不超过\(100\)个,由一个数字\(0\)结束。有些杂务没有需要准备的工作只描述一个单独的\(0\),整个输入文件中不会出现多余的空格。
一个整数,表示完成所有杂务所需的最短时间。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e6 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
struct node
{
int to, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int in[N], vol[N];
int f[N];
void topo()
{
queue<int> q;
for (int i = 1; i <= n; ++i)
if (!in[i])
q.push(i), f[i] = vol[i];
while (!q.empty())
{
int u = q.front();
q.pop();
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
in[v]--;
f[v] = max(f[v], f[u] + vol[v]);
if (!in[v])
q.push(v);
}
}
}
int main()
{
n = read();
for (int i = 1; i <= n; ++i)
{
int u = read(), v;
vol[i] = read();
while (1)
{
v = read();
if (!v)
break;
add_edge(v, u);
in[u]++;
}
}
topo();
int ans = 0;
for (int i = 1; i <= n; ++i)
ans = max(ans, f[i]);
printf("%d\n", ans);
return 0;
}
Index 4:
一条单向的铁路线上,依次有编号为 $1, 2, …, n $的 $n $个火车站。每个火车站都有一个级别,最低为 \(1\) 级。现有若干趟车次在这条线路上行驶,每一趟都满足如下要求:如果这趟车次停靠了火车站 \(x\),则始发站、终点站之间所有级别大于等于火车站$ x$ 的都必须停靠。(注意:起始站和终点站自然也算作事先已知需要停靠的站点)
例如,下表是$ 5 \(趟车次的运行情况。其中,前\) 4$ 趟车次均满足要求,而第 \(5\) 趟车次由于停靠了 \(3\) 号火车站(\(2\) 级)却未停靠途经的 \(6\) 号火车站(亦为 \(2\) 级)而不满足要求。
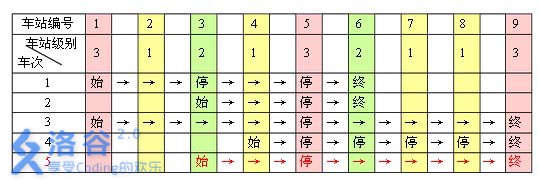
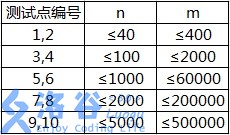
现有 \(m\) 趟车次的运行情况(全部满足要求),试推算这$ n$ 个火车站至少分为几个不同的级别。
第一行包含 \(2\) 个正整数 \(n, m\),用一个空格隔开。
第 \(i + 1\) 行\((1 ≤ i ≤ m)\)中,首先是一个正整数 \(s_i(2 ≤ s_i ≤ n)\),表示第$ i$ 趟车次有 \(s_i\) 个停靠站;接下来有$ s_i$个正整数,表示所有停靠站的编号,从小到大排列。每两个数之间用一个空格隔开。输入保证所有的车次都满足要求。
一个正整数,即 \(n\) 个火车站最少划分的级别数。
对于$ 20%$的数据,\(1 ≤ n, m ≤ 10\);
对于 \(50\%\)的数据,\(1 ≤ n, m ≤ 100\);
对于 \(100\%\)的数据,\(1 ≤ n, m ≤ 1000\)。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e3 + 50;
const int M = 2e6 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
bool vis[N];
bool rep[N][N];
int a[N], in[N];
struct node
{
int to, nxt;
} e[M];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
queue<int> q;
int f[N];
void topo()
{
int ans = 0;
for (int i = 1; i <= n; ++i)
if (!in[i])
q.push(i);
while (!q.empty())
{
int u = q.front();
q.pop();
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
f[v] = f[u] + 1;
ans = max(ans, f[v]);
in[v]--;
if (!in[v])
q.push(v);
}
}
printf("%d\n", ans + 1);
}
int main()
{
n = read(), m = read();
for (int i = 1; i <= m; ++i)
{
memset(vis, 0, sizeof(vis));
int nn = read();
for (int j = 1; j <= nn; ++j)
a[j] = read(), vis[a[j]] = 1;
for (int j = a[1]+1; j <= a[nn]; ++j)
{
if (!vis[j])
{
for (int k = 1; k <= nn; ++k)
{
if (!rep[j][a[k]])
{
rep[j][a[k]] = 1;
add_edge(j, a[k]);
in[a[k]]++;
}
}
}
}
}
topo();
return 0;
}
欧拉路
- \(Euler~Path\)
Q:什么是欧拉路
A:类似一笔画
引入概念:欧拉回路指一笔画的起点与终点相同。
Index 1:
题目大意:有一种由彩色珠子连接而成的项链。每个珠子的两半由不同颜色组成。如图所示,相邻两个珠子在接触的地方颜色相同。现在有一些零碎的珠子,需要确认它们是否可以复原成完整的项链。
输入格式:输入第一行为测试数据组数 \(T\) 。每组数据的第一行是一个整数 \(N (5 \leq N \leq 1000)\),表示珠子的个数。接下来的 \(N\) 行每行包含两个整数,即珠子两半的颜色。颜色用 \(1\sim50\) 的整数来表示。
输出格式:对于每组数据,输出测试数据编号和方案。如果无解,输出some beads may be lost。方案的格式和输入相同,也是一共 \(N\) 行,每行用两个整数描述一个珠子(从左到右的顺序),其中第一个整数表示左半的颜色,第二个整数表示右半的颜色。根据题目规定,对于 \(1\leq i\leq N\),第 \(i\) 行的第二个数必须等于第 \(i+1\) 行上的第一个数,且第 \(N\) 行的第二个数必须等于第一行的第一个数(因为项链是环形的)。如果有多解,输出任意一组即可。在相邻两组输出之间应有一个空行。
输出任意欧拉回路不是此题的难点
难点在于如何判断是否有路
Aim 1:欧拉性质
环境为连通图
研究表明,如果一个图所有点的度为偶数,则存在欧拉回路。
度即入度与出度之和,换而言之,此节点连接的边数。
tip: 将珠子看成边。
暂时弃坑:2023-1-16
分层图
- \(Layered~Graph\)
分层图适用于解决最短路上有额外条件的问题。
Index 1:
我们考虑最简单的旅行问题吧: 现在这个大陆上有 \(N\) 个城市,\(M\) 条双向的道路。城市编号为 \(1\) ~ \(N\),我们在 \(1\) 号城市,需要到 \(N\) 号城市,怎样才能最快地到达呢?
这不就是最短路问题吗?我们都知道可以用 Dijkstra、Bellman-Ford、Floyd-Warshall等算法来解决。
现在,我们一共有 \(K\) 张可以使时间变慢 50%的 SpellCard,也就是说,在通过某条路径时,我们可以选择使用一张卡片,这样,我们通过这一条道路的时间 就可以减少到原先的一半。需要注意的是:
- 在一条道路上最多只能使用一张 SpellCard。
- 使用一张SpellCard 只在一条道路上起作用。
- 你不必使用完所有的 SpellCard。
给定以上的信息,你的任务是:求出在可以使用这不超过 \(K\) 张时间减速的 SpellCard 之情形下,从城市 \(1\) 到城市 \(N\) 最少需要多长时间。
第一行包含三个整数:\(N\)、\(M\)、\(K\)。
接下来 \(M\) 行,每行包含三个整数:\(A_i\)、\(B_i\)、\(Time_i\),表示存在一条 \(A_i\) 与 \(B_i\) 之间的双向道路,在不使用 SpellCard 之前提下,通过它需要 \(Time_i\) 的时间。
输出一个整数,表示从 \(1\) 号城市到 \(N\) 号城市的最小用时。
对于 \(100\%\) 的数据,保证:
- \(1 \leq K \leq N \leq 50\),\(M \leq 10^3\)。
- \(1 \leq A_i,B_i \leq N\),\(2 \leq Time_i \leq 2 \times 10^3\)。
- 为保证答案为整数,保证所有的 \(Time_i\) 均为偶数。
- 所有数据中的无向图保证无自环、重边,且是连通的。
Aim 1:如何分层
我们需要将第 \(1\) 层到第 \(k\) 层,都向上面一层连一条边,这条边就是使用特殊权利的边,我们之所以不会担心其超过 \(k\) 次使用,这因为我们建的特权边就最多有 \(k\) 次。
具体细节看代码,最短路不用讲的,所以这题难点只在建边的过程中。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m, k;
struct edge
{
int to, dis, nxt;
} e[N << 1];
int head[N], cnt;
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
struct node
{
int dis, pos;
bool operator<(const node &x) const
{
return x.dis < dis;
}
};
priority_queue<node> q;
int dis[N];
bool vis[N];
void dij()
{
memset(dis, 0x3f3f3f3f, sizeof(dis));
dis[1] = 0;
q.push((node){0, 1});
while (!q.empty())
{
node tmp = q.top();
q.pop();
int x = tmp.pos;
if (vis[x])
continue;
vis[x] = 1;
for (int i = head[x]; i; i = e[i].nxt)
{
int y = e[i].to;
if (dis[y] > dis[x] + e[i].dis)
{
dis[y] = dis[x] + e[i].dis;
if (!vis[y])
{
q.push((node){dis[y], y});
}
}
}
}
int res = Mod;
for (int i = 0; i <= k; ++i)
{
res = min(res, dis[i * n + n]);
}
printf("%d\n", res);
}
int main()
{
n = read(), m = read(), k = read();
for (int i = 1; i <= m; ++i)
{
int u = read(), v = read(), w = read();
for (int j = 0; j <= k; ++j)
{
add_edge(j * n + u, j * n + v, w);
add_edge(j * n + v, j * n + u, w);
add_edge(j * n + u, (j + 1) * n + v, w / 2);
add_edge(j * n + v, (j + 1) * n + u, w / 2);
}
}
dij();
return 0;
}
Index 2:
Alice 和 Bob 现在要乘飞机旅行,他们选择了一家相对便宜的航空公司。该航空公司一共在 \(n\) 个城市设有业务,设这些城市分别标记为 \(0\) 到 \(n-1\),一共有 \(m\) 种航线,每种航线连接两个城市,并且航线有一定的价格。
Alice 和 Bob 现在要从一个城市沿着航线到达另一个城市,途中可以进行转机。航空公司对他们这次旅行也推出优惠,他们可以免费在最多 \(k\) 种航线上搭乘飞机。那么 Alice 和 Bob 这次出行最少花费多少?
第一行三个整数 \(n,m,k\),分别表示城市数,航线数和免费乘坐次数。
接下来一行两个整数 \(s,t\),分别表示他们出行的起点城市编号和终点城市编号。
接下来 \(m\) 行,每行三个整数 \(a,b,c\),表示存在一种航线,能从城市 \(a\) 到达城市 \(b\),或从城市 \(b\) 到达城市 \(a\),价格为 \(c\)。
输出一行一个整数,为最少花费。
对于 \(100\%\) 的数据,\(2 \le n \le 10^4\),\(1 \le m \le 5\times 10^4\),\(0 \le k \le 10\),\(0\le s,t,a,b\le n\),\(a\ne b\),\(0\le c\le 10^3\)。
做分层图的题,一定要注意数据范围,血的教训。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 3e6 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m, k;
int s, t;
struct edge
{
int to, dis, nxt;
} e[N << 1];
int head[N], cnt;
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int dis[N];
bool vis[N];
struct node
{
int pos, dis;
bool operator<(const node &x) const
{
return x.dis < dis;
}
};
priority_queue<node> q;
void dij(int s)
{
memset(dis, 0x3f, sizeof(dis));
dis[s] = 0;
q.push((node){s, 0});
while (!q.empty())
{
node tmp = q.top();
q.pop();
int x = tmp.pos;
if (vis[x])
continue;
vis[x] = 1;
for (int i = head[x]; i; i = e[i].nxt)
{
int y = e[i].to;
if (dis[y] > dis[x] + e[i].dis)
{
dis[y] = dis[x] + e[i].dis;
if (!vis[y])
{
q.push((node){y, dis[y]});
}
}
}
}
int res = Mod;
for (int i = 0; i <= k; ++i)
{
res = min(res, dis[t + i * n]);
}
printf("%d\n", res);
}
int main()
{
n = read(), m = read(), k = read();
s = read(), t = read();
for (int i = 1; i <= m; ++i)
{
int u = read(), v = read(), w = read();
add_edge(u, v, w);
add_edge(v, u, w);
for (int j = 1; j <= k; ++j)
{
add_edge(u + j * n, v + j * n, w);
add_edge(v + j * n, u + j * n, w);
add_edge(u + (j - 1) * n, v + j * n, 0);
add_edge(v + (j - 1) * n, u + j * n, 0);
}
}
dij(s);
return 0;
}
Index 3:
多年以后,笨笨长大了,成为了电话线布置师。由于地震使得某市的电话线全部损坏,笨笨是负责接到震中市的负责人。该市周围分布着 \(1\le N\le1000\) 根据 \(1\cdots N\) 顺序编号的废弃的电话线杆,任意两根线杆之间没有电话线连接,一共有 \(1\le p\le10000\) 对电话杆可以拉电话线。其他的由于地震使得无法连接。
第i对电线杆的两个端点分别是 \(a_i\) ,\(b_i\),它们的距离为 \(1\le l_i\le1000000\)。数据中每对 \((a_i,b_i)\) 只出现一次。编号为 \(1\) 的电话杆已经接入了全国的电话网络,整个市的电话线全都连到了编号 \(N\) 的电话线杆上。也就是说,笨笨的任务仅仅是找一条将 \(1\) 号和 \(N\) 号电线杆连起来的路径,其余的电话杆并不一定要连入电话网络。
电信公司决定支援灾区免费为此市连接 \(k\) 对由笨笨指定的电话线杆,对于此外的那些电话线,需要为它们付费,总费用决定于其中最长的电话线的长度(每根电话线仅连接一对电话线杆)。如果需要连接的电话线杆不超过 \(k\) 对,那么支出为 \(0\)。
请你计算一下,将电话线引导震中市最少需要在电话线上花多少钱?
输入文件的第一行包含三个数字 \(n,p,k\)。
第二行到第 \(p+1\) 行,每行分别都为三个整数 \(a_i,b_i,l_i\)。
一个整数,表示该项工程的最小支出,如果不可能完成则输出 -1。
最短路变形,求最大值,一定要看清题目,否则会像我一样挂分。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 2e6 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m, k;
struct edge
{
int to, dis, nxt;
} e[N << 1];
int head[N], cnt;
bool vis[N];
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int dis[N];
struct node
{
int pos, dis;
bool operator<(const node &x) const
{
return x.dis < dis;
}
};
priority_queue<node> q;
void dij()
{
memset(dis, 0x3f3f3f3f, sizeof(dis));
dis[1] = 0;
q.push((node){1, 0});
while (!q.empty())
{
node tmp = q.top();
q.pop();
int x = tmp.pos;
if (vis[x])
continue;
vis[x] = 1;
for (int i = head[x]; i; i = e[i].nxt)
{
int y = e[i].to;
if (dis[y] > max(dis[x], e[i].dis))
{
dis[y] = max(dis[x], e[i].dis);
if (!vis[y])
{
q.push((node){y, dis[y]});
}
}
}
}
int Min = 0x3f3f3f3f;
for (int i = 0; i <= k; ++i)
{
Min = min(Min, dis[i * n + n]);
}
if (Min == 0x3f3f3f3f)
{
printf("-1\n");
}
else
{
printf("%d\n", Min);
}
}
int main()
{
n = read(), m = read(), k = read();
for (int i = 1; i <= m; ++i)
{
int u = read(), v = read(), w = read();
add_edge(u, v, w);
add_edge(v, u, w);
for (int j = 1; j <= k; ++j)
{
add_edge(j * n + u, j * n + v, w);
add_edge(j * n + v, j * n + u, w);
add_edge((j - 1) * n + u, j * n + v, 0);
add_edge((j - 1) * n + v, j * n + u, 0);
}
}
dij();
return 0;
}
高级数据结构
分块
- \(Block\)
优雅+暴力
kawayi~~
Index 1:
给出一个长为 \(n\) 的数列,以及 \(n\) 个操作,操作涉及区间加法,询问区间内小于某个值 \(x\) 的元素个数。
第一行输入一个数字 \(n\)。
第二行输入 \(n\) 个数字,第 \(i\) 个数字为 \(a_i\),以空格隔开。
接下来输入 n 行询问,每行输入四个数字 \(\mathrm{opt}、l、r、c\),以空格隔开。
若 \(\mathrm{opt} = 0\),表示将位于 \([l, r]\) 的之间的数字都加 \(c\)。
若 \(\mathrm{opt} = 1\),表示询问 \([l, r]\) 中,小于 \(c^2\) 的数字的个数。
对于 \(100\%\) 的数据,\(1 \leq n \leq 50000, -2^{31} \leq \mathrm{others}、\mathrm{ans} \leq 2^{31}-1\)。
分块的基本思想,整体的一起解决,琐碎的暴力解决,尽可能地压缩时间。
但是我们需要注意分块地适应范围可以说很广也可以说很窄,广在可以运用在方方面面,窄在数据范围地要求较高。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
int a[N], b[N];
int add[N];
int block,num;
int pos[N];
int L[N], R[N];
void update(int x)
{
for (int i = L[pos[x]]; i <= R[pos[x]]; ++i)
b[i] = a[i];
sort(b + L[pos[x]], b + R[pos[x]] + 1);
}
int main()
{
n = read();
block = sqrt(n);
num=n/block;
if (n % block)
num++;
for (int i = 1; i <= n; ++i)
a[i] = read(), b[i] = a[i];
for (int i = 1; i <= num; ++i)
L[i] = (i - 1) * block + 1, R[i] = i * block;
R[num] = n;
for (int i = 1; i <= n; ++i)
pos[i] = (i - 1) / block + 1;
for (int i = 1; i <= num; ++i)
{
sort(b + L[i], b + R[i] + 1);
}
for (int i = 1; i <= n; ++i)
{
int opt = read(), l = read(), r = read(), c = read();
if (opt == 0)
{
if (pos[l] == pos[r])
{
for (int i = l; i <= r; ++i)
a[i] += c;
update(l);
}
else
{
for (int i = l; i <= R[pos[l]]; ++i)
a[i] += c;
update(l);
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
add[i] += c;
for (int i = L[pos[r]]; i <= r; ++i)
a[i] += c;
update(r);
}
}
else
{
c *= c;
int ans = 0;
if (pos[l] == pos[r])
{
for (int i = l; i <= r; ++i)
if (a[i] + add[pos[l]] < c)
++ans;
}
else
{
for (int i = l; i <= R[pos[l]]; ++i)
if (a[i] + add[pos[l]] < c)
++ans;
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
{
int it = lower_bound(b + L[i], b + R[i] + 1, c - add[i]) - b - 1;
ans += it - L[i] + 1;
}
for (int i = L[pos[r]]; i <= r; ++i)
if (a[i] + add[pos[r]] < c)
++ans;
}
printf("%d\n", ans);
}
}
return 0;
}
Index 2:
给出一个长为 \(n\) 的数列,以及 \(n\) 个操作,操作涉及区间加法,询问区间内小于某个值 \(x\) 的元素个数。
第一行输入一个数字 \(n\)。
第二行输入 \(n\) 个数字,第 \(i\) 个数字为 \(a_i\),以空格隔开。
接下来输入 n 行询问,每行输入四个数字 \(\mathrm{opt}、l、r、c\),以空格隔开。
若 \(\mathrm{opt} = 0\),表示将位于 \([l, r]\) 的之间的数字都加 \(c\)。
若 \(\mathrm{opt} = 1\),表示询问 \([l, r]\) 中,\(c\) 的前驱。
对于 \(100\%\) 的数据,\(1 \leq n \leq 100000, -2^{31} \leq \mathrm{others}、\mathrm{ans} \leq 2^{31}-1\)。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N], b[N];
int add[N];
int block, num;
int pos[N];
int L[N], R[N];
void update(int x)
{
for (int i = L[pos[x]]; i <= R[pos[x]]; ++i)
b[i] = a[i];
sort(b + L[pos[x]], b + R[pos[x]] + 1);
}
signed main()
{
n = read();
block = sqrt(n);
num = n / block;
if (n % block)
num++;
for (int i = 1; i <= n; ++i)
a[i] = read(), b[i] = a[i];
for (int i = 1; i <= num; ++i)
L[i] = (i - 1) * block + 1, R[i] = i * block;
R[num] = n;
for (int i = 1; i <= n; ++i)
pos[i] = (i - 1) / block + 1;
for (int i = 1; i <= num; ++i)
{
sort(b + L[i], b + R[i] + 1);
}
m = n;
while (m--)
{
int opt = read(), l = read(), r = read(), c = read();
if (opt == 0)
{
if (pos[l] == pos[r])
{
for (int i = l; i <= r; ++i)
a[i] += c;
update(l);
}
else
{
for (int i = l; i <= R[pos[l]]; ++i)
a[i] += c;
update(l);
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
add[i] += c;
for (int i = L[pos[r]]; i <= r; ++i)
a[i] += c;
update(r);
}
}
else
{
int ans = -1;
if (pos[l] == pos[r])
{
for (int i = l; i <= r; ++i)
if (a[i] + add[pos[l]] < c)
ans = max(ans, a[i] + add[pos[l]]);
}
else
{
for (int i = l; i <= R[pos[l]]; ++i)
if (a[i] + add[pos[l]] < c)
ans = max(ans, a[i] + add[pos[l]]);
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
{
int it = lower_bound(b + L[i], b + R[i] + 1, c - add[i]) - b - 1;
if (it >= L[i])
{
ans = max(ans, b[it] + add[i]);
}
}
for (int i = L[pos[r]]; i <= r; ++i)
if (a[i] + add[pos[r]] < c)
ans = max(ans, a[i] + add[pos[r]]);
}
printf("%lld\n", ans);
}
}
return 0;
}
Index 3:
给出一个长为 \(n\) 的数列,以及 \(n\) 个操作,操作涉及区间加法,区间求和。
第一行输入一个数字 \(n\)。
第二行输入 \(n\) 个数字,第 \(i\) 个数字为 \(a_i\),以空格隔开。
接下来输入 \(n\) 行询问,每行输入四个数字 \(\mathrm{opt}、l、r、c\),以空格隔开。
若 \(\mathrm{opt} = 0\),表示将位于 \([l, r]\) 的之间的数字都加 \(c\)。
若 \(\mathrm{opt} = 1\),表示询问位于 \([l, r]\) 的所有数字的和 \(\bmod (c+1)\)。
对于 \(100\%\) 的数据,\(1 \leq n \leq 50000, -2^{31} \leq \mathrm{others}、\mathrm{ans} \leq 2^{31}-1\)。
警示后人:不要没事干就
草mod
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 5e4 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N];
int sum[N], add[N];
int block, num;
int L[N], R[N];
int pos[N];
signed main()
{
n = read();
for (int i = 1; i <= n; ++i)
a[i] = read();
block = sqrt(n);
num = n / block;
if (n % block)
++num;
for (int i = 1; i <= num; ++i)
L[i] = (i - 1) * block + 1, R[i] = i * block;
R[num] = n;
for (int i = 1; i <= num; ++i)
for (int j = L[i]; j <= R[i]; ++j)
pos[j] = i, sum[i] += a[j];
m = n;
while (m--)
{
int opt = read(), l = read(), r = read(), c = read();
if (opt == 0)
{
if (pos[l] == pos[r])
{
sum[pos[l]] += (r - l + 1) * c;
for (int i = l; i <= r; ++i)
a[i] += c;
}
else
{
sum[pos[l]] += (R[pos[l]] - l + 1) * c;
for (int i = l; i <= R[pos[l]]; ++i)
a[i] += c;
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
add[i] += c;
sum[pos[r]] += (r - L[pos[r]] + 1) * c;
for (int i = L[pos[r]]; i <= r; ++i)
a[i] += c;
}
}
else
{
++c;
int ans = 0;
if (pos[l] == pos[r])
{
for (int i = l; i <= r; ++i)
ans += a[i];
ans += (r - l + 1) * add[pos[l]];
ans %= c;
}
else
{
for (int i = l; i <= R[pos[l]]; ++i)
ans += a[i];
ans += (R[pos[l]] - l + 1) * add[pos[l]];
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
ans += sum[i] + (R[i] - L[i] + 1) * add[i];
for (int i = L[pos[r]]; i <= r; ++i)
ans += a[i];
ans += (r - L[pos[r]] + 1) * add[pos[r]];
ans %= c;
}
printf("%lld\n", ans);
}
}
return 0;
}
Index 4:
给出一个长为 \(n\) 的数列,以及 \(n\) 个操作,操作涉及区间乘法,区间加法,单点询问。
第一行输入一个数字 \(n\)。
第二行输入 \(n\) 个数字,第 \(i\) 个数字为 \(a_i\),以空格隔开。
接下来输入 \(n\) 行询问,每行输入四个数字 \(\mathrm{opt}、l、r、c\),以空格隔开。
若 \(\mathrm{opt} = 0\),表示将位于 \([l, r]\) 的之间的数字都加 \(c\)。
若 \(\mathrm{opt} = 1\),表示将位于 \([l, r]\) 的之间的数字都乘 \(c\)。
若 \(\mathrm{opt} = 2\),表示询问 \(a_r\) 的值 \(\mathop{\mathrm{mod}} 10007\)(\(l\) 和 \(c\) 忽略)。
对于 \(100\%\) 的数据,\(1 \leq n \leq 100000, -2^{31} \leq \mathrm{others}、\mathrm{ans} \leq 2^{31}-1\)。
在处理碎片化数据时,遍历整个块,修改数组值。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 10007;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N];
int pos[N];
int L[N], R[N];
int block, num;
int add[N], mul[N];
void push_down(int x)
{
for (int i = L[pos[x]]; i <= R[pos[x]]; ++i)
a[i] *= mul[pos[i]], a[i] += add[pos[i]], a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
add[pos[x]] = 0;
mul[pos[x]] = 1;
}
signed main()
{
n = read();
for (int i = 1; i <= n; ++i)
a[i] = read();
block = sqrt(n);
num = n / block;
if (n % block)
++num;
for (int i = 1; i <= num; ++i)
L[i] = (i - 1) * block + 1, R[i] = i * block, mul[i] = 1;
R[num] = n;
for (int i = 1; i <= num; ++i)
{
for (int j = L[i]; j <= R[i]; ++j)
pos[j] = i;
}
m = n;
while (m--)
{
int opt = read(), l = read(), r = read(), c = read() % Mod;
if (opt == 0)
{
if (pos[l] == pos[r])
{
push_down(l);
for (int i = l; i <= r; ++i)
a[i] += c, a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
}
else
{
push_down(l);
for (int i = l; i <= R[pos[l]]; ++i)
a[i] += c, a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
add[i] += c;
push_down(r);
for (int i = L[pos[r]]; i <= r; ++i)
a[i] += c, a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
}
}
else if (opt == 1)
{
if (pos[l] == pos[r])
{
push_down(l);
for (int i = l; i <= r; ++i)
a[i] *= c, a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
}
else
{
push_down(l);
for (int i = l; i <= R[pos[l]]; ++i)
a[i] *= c, a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
mul[i] *= c, add[i] *= c, mul[i] = mul[i] >= Mod ? mul[i] % Mod : mul[i], add[i] = add[i] > Mod ? add[i] % Mod : add[i];
push_down(r);
for (int i = L[pos[r]]; i <= r; ++i)
a[i] *= c, a[i] = a[i] >= Mod ? a[i] % Mod : a[i];
}
}
else
{
int ans = a[r];
ans *= mul[pos[r]];
ans += add[pos[r]];
ans = ans >= Mod ? ans % Mod : ans;
printf("%lld\n", ans);
}
}
return 0;
}
Index 5:
给出一个长为 \(n\) 的数列,以及 \(n\) 个操作,操作涉及区间询问等于一个数 \(c\) 的元素,并将这个区间的所有元素改为 \(c\)。
第一行输入一个数字 \(n\)。
第二行输入 \(n\) 个数字,第 \(i\) 个数字为 \(a_i\),以空格隔开。
接下来输入 \(n\) 行询问,每行输入三个数字 \(l、r、c\),以空格隔开。
表示先查询位于 \([l,r]\) 的数字有多少个是 \(c\),再把位于 \([l,r]\) 的数字都改为 \(c\)。
对于 \(100\%\) 的数据,\(1 \leq n \leq 100000, -2^{31} \leq \mathrm{others}、\mathrm{ans} \leq 2^{31}-1\)。
分块的思想就是暴力,所以还是按原来的写。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N];
int pos[N];
int L[N], R[N];
int block, num;
int alt[N];
void push_down(int x)
{
if (alt[pos[x]] == -1)
return;
for (int i = L[pos[x]]; i <= R[pos[x]]; ++i)
a[i] = alt[pos[x]];
alt[pos[x]] = -1;
}
int main()
{
n = read();
for (int i = 1; i <= n; ++i)
a[i] = read();
block = sqrt(n);
num = n / block;
if (n % block)
++num;
for (int i = 1; i <= num; ++i)
L[i] = (i - 1) * block + 1, R[i] = i * block;
R[num] = n;
for (int i = 1; i <= num; ++i)
{
for (int j = L[i]; j <= R[i]; ++j)
pos[j] = i;
alt[i] = -1;
}
m = n;
while (m--)
{
int l = read(), r = read(), c = read();
int ans = 0;
if (pos[l] == pos[r])
{
if (alt[pos[l]] != -1)
{
if (alt[pos[l]] == c)
ans += r - l + 1;
}
else
{
for (int i = l; i <= r; ++i)
ans += (a[i] == c);
}
}
else
{
if (alt[pos[l]] != -1)
{
if (alt[pos[l]] == c)
ans += R[pos[l]] - l + 1;
}
else
{
for (int i = l; i <= R[pos[l]]; ++i)
ans += (a[i] == c);
}
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
{
if (alt[i] != -1)
{
if (alt[i] == c)
ans += R[i] - L[i] + 1;
}
else
{
for (int j = L[i]; j <= R[i]; ++j)
ans += (a[j] == c);
}
}
if (alt[pos[r]] != -1)
{
if (alt[pos[r]] == c)
ans += r - L[pos[r]] + 1;
}
else
{
for (int i = L[pos[r]]; i <= r; ++i)
ans += (a[i] == c);
}
}
printf("%d\n", ans);
if (pos[l] == pos[r])
{
push_down(l);
for (int i = l; i <= r; ++i)
a[i] = c;
}
else
{
push_down(l);
for (int i = l; i <= R[pos[l]]; ++i)
a[i] = c;
for (int i = pos[l] + 1; i <= pos[r] - 1; ++i)
alt[i] = c;
push_down(r);
for (int i = L[pos[r]]; i <= r; ++i)
a[i] = c;
}
}
return 0;
}
RMQ
- \(Range~Maximum/Minimum~Query\)
此类型唯一的用途是查询区间极值。
限制不可修改,范围由于倍增的原因,时间极低,适应能力强。
Index 1:
每天,农夫 John 的 \(n(1\le n\le 5\times 10^4)\) 头牛总是按同一序列排队。
有一天, John 决定让一些牛们玩一场飞盘比赛。他准备找一群在队列中位置连续的牛来进行比赛。但是为了避免水平悬殊,牛的身高不应该相差太大。John 准备了 \(q(1\le q\le 1.8\times10^5)\) 个可能的牛的选择和所有牛的身高 \(h_i(1\le h_i\le 10^6,1\le i\le n)\)。他想知道每一组里面最高和最低的牛的身高差。
第一行两个数 \(n,q\)。
接下来 \(n\) 行,每行一个数 \(h_i\)。
再接下来 \(q\) 行,每行两个整数 \(a\) 和 \(b\),表示询问第 \(a\) 头牛到第 \(b\) 头牛里的最高和最低的牛的身高差。
输出共 \(q\) 行,对于每一组询问,输出每一组中最高和最低的牛的身高差。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, q;
int a[N];
int Min[N][30];
int Max[N][30];
int query_max(int l, int r)
{
int k = log2(r - l + 1);
return max(Max[l][k], Max[r - (1 << k) + 1][k]);
}
int query_min(int l, int r)
{
int k = log2(r - l + 1);
return min(Min[l][k], Min[r - (1 << k) + 1][k]);
}
int main()
{
n = read(), q = read();
for (int i = 1; i <= n; ++i)
a[i] = read(), Min[i][0] = Max[i][0] = a[i];
for (int j = 1; (1 << j) <= n; ++j)
{
for (int i = 1; i + (1 << j) - 1 <= n; ++i)
{
Min[i][j] = min(Min[i][j - 1], Min[i + (1 << j - 1)][j - 1]);
Max[i][j] = max(Max[i][j - 1], Max[i + (1 << j - 1)][j - 1]);
}
}
while (q--)
{
int l = read(), r = read();
printf("%d\n", query_max(l, r) - query_min(l, r));
}
return 0;
}
是不是觉得RMQ很没用
但是如果没有修改的话你写线段树,岂不是大材小用,不仅代码拥挤,也不容易调试。
树状数组
- \(Binary~Indexed~Tree(BIT)\)
用于区间加速查询,修改,强有力的时间效率,简单而又精悍的代码,巧妙的思维带您领略数据结构的入门篇章。
tree[] 表示树状数组
k 表示 i 二进制下末尾 0 的个数
那么 \(tree_i=\sum^{i}_{j=i-2^k+1}a_j\)
建议手动枚举前几位寻找其规律。
Index 1:
输入数据的第一行为 X n m,代表矩阵大小为 \(n\times m\)。
从输入数据的第二行开始到文件尾的每一行会出现以下两种操作:
L a b c d delta—— 代表将 \((a,b),(c,d)\) 为顶点的矩形区域内的所有数字加上 \(delta\)。k a b c d—— 代表求 \((a,b),(c,d)\) 为顶点的矩形区域内所有数字的和。
针对每个 \(k\) 操作,在单独的一行输出答案。
对于 \(100\%\) 的数据,\(1 \le n \le 2048\),\(1 \le m \le 2048\),\(-500 \le delta \le 500\),操作不超过 \(2\times 10^5\) 个,保证运算过程中及最终结果均不超过 \(32\) 位带符号整数类型的表示范围。
二维区间修改+区间查询
Aim 1: 区间修改
\(d[i][j]\) 为原数组的差分数组。
\]
\]
Aim 2: 区间查询
\]
\]
\]
因此维护四个树状数组,维护\(\sum\)
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 2050;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int tree1[N][N], tree2[N][N], tree3[N][N], tree4[N][N];
int lowbit(int x) { return x & (-x); }
void update(int x, int y, int d)
{
for (int i = x; i <= n; i += lowbit(i))
{
for (int j = y; j <= m; j += lowbit(j))
{
tree1[i][j] += d;
tree2[i][j] += d * x;
tree3[i][j] += d * y;
tree4[i][j] += d * x * y;
}
}
}
int query(int x, int y)
{
int res = 0;
for (int i = x; i > 0; i -= lowbit(i))
{
for (int j = y; j > 0; j -= lowbit(j))
{
res += (x + 1) * (y + 1) * tree1[i][j] - (y + 1) * tree2[i][j] - (x + 1) * tree3[i][j] + tree4[i][j];
}
}
return res;
}
char ch[2];
int main()
{
n = read(), m = read();
while (scanf("%s", ch) != EOF)
{
if (ch[0] == 'L')
{
int a = read(), b = read(), c = read(), d = read(), delta = read();
update(a, b, delta);
update(c + 1, b, -delta);
update(a, d + 1, -delta);
update(c + 1, d + 1, delta);
}
else
{
int a = read(), b = read(), c = read(), d = read();
printf("%d\n", query(c, d) - query(c, b - 1) - query(a - 1, d) + query(a - 1, b - 1));
}
}
return 0;
}
Index 2:
对于给定的一段正整数序列,逆序对就是序列中 \(a_i>a_j\) 且 \(i<j\) 的有序对。
第一行,一个数 \(n\),表示序列中有 \(n\)个数。
第二行 \(n\) 个数,表示给定的序列。序列中每个数字不超过 \(10^9\)。
对于 \(100\%\) 的数据,\(n \leq 5 \times 10^5\)
单点修改+区间查询
Aim 1: 如何转化
我们从大到小依次添加,在相应位置加 \(1\)。
每次答案为这个位置前的数之和,可以用树状数组解决。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 5e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
struct node
{
int ord, vol;
} a[N];
bool cmp(node x, node y)
{
return x.vol >= y.vol;
}
int tree[N];
int lowbit(int x) { return x & (-x); }
void update(int x, int d)
{
for (int i = x; i <= n; i += lowbit(i))
{
tree[i] += d;
}
}
int query(int x)
{
int res = 0;
for (int i = x; i > 0; i -= lowbit(i))
{
res += tree[i];
}
return res;
}
signed main()
{
n = read();
for (int i = 1; i <= n; ++i)
a[i].ord = i, a[i].vol = read();
stable_sort(a + 1, a + n + 1, cmp);
int ans = 0;
for (int i = 1; i <= n; ++i)
{
update(a[i].ord, 1);
ans += query(a[i].ord - 1);
}
printf("%lld\n", ans);
return 0;
}
Index 3:
有一个 n 个元素的数组,每个元素初始均为 0。
第一行包含两个整数 n, m,表示数组的长度和指令的条数; 以下 m 行,每行的第一个数 t 表示操作的种类.
若 t = 1,则接下来有两个数 L R,表示区间 [L, R] 的每个数均反转; 若 t = 2,则接下来只有一个数 i,表示询问的下标。
对于 \(100\%\) 的数据,\(1 ≤ n ≤ 10^5\), \(1 ≤ m ≤ 5 × 10^5\),保证 \(L ≤ R\)。
Aim 1:简易变形
我们可以发现,原来的差分修改只是变成了异或修改。
此时翻转 \(l \sim r\) , 仅需修改 \(a[l],a[r+1]\).
第 \(i\) 个数的值为 \(a[1]~xor~a[2]~\cdots xor~a[i]\)
xor 表示 异或运算。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int tree[N];
int lowbit(int x) { return x & (-x); }
void update(int x)
{
for (int i = x; i <= n; i += lowbit(i))
{
tree[i] ^= 1;
}
}
int query(int x)
{
int res = 0;
for (int i = x; i > 0; i -= lowbit(i))
{
res ^= tree[i];
}
return res;
}
int main()
{
n = read(), m = read();
while (m--)
{
int opt = read();
if (opt == 1)
{
int l = read(), r = read();
update(l);
update(r + 1);
}
else
{
int q = read();
printf("%d\n", query(q));
}
}
return 0;
}
Index 4:
第一行为两个整数 \(n\) 和 \(m\),\(n\) 表示防线长度,\(m\) 表示 SCV 布雷次数及小 FF 询问的次数总和。
接下来有 \(m\) 行,每行三个整数 \(q,l,r\):
- 若 \(q=1\),则表示 SCV 在 \([l, r]\) 这段区间布上一种地雷;
- 若 \(q=2\),则表示小 FF 询问当前 \([l, r]\) 区间总共有多少种地雷。
对于 \(100\%\) 的数据,\(0 \le n\),\(m \le 10^5\)。
Aim 1:快速统计
就是当前的开头-结尾。
That’s enough!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int tree1[N], tree2[N];
int lowbit(int x)
{
return x & (-x);
}
void update_start(int x, int k)
{
for (int i = x; i <= n; i += lowbit(i))
{
tree1[i] += k;
}
}
void update_end(int x, int k)
{
for (int i = x; i <= n; i += lowbit(i))
{
tree2[i] += k;
}
}
int query_start(int x)
{
int res = 0;
for (int i = x; i > 0; i -= lowbit(i))
{
res += tree1[i];
}
return res;
}
int query_end(int x)
{
int res = 0;
for (int i = x; i > 0; i -= lowbit(i))
{
res += tree2[i];
}
return res;
}
int main()
{
n = read(), m = read();
while (m--)
{
int opt = read(), l = read(), r = read();
if (opt == 1)
{
update_start(l, 1);
update_end(r, 1);
}
else
{
printf("%d\n", query_start(r) - query_end(l - 1));
}
}
return 0;
}
Index 5:
一种名为 Tetris Attack 的猜谜游戏风靡 Byteotia。游戏本身非常复杂,因此我们只介绍它的简化规则:
玩家拥有一个有 \(2n\) 个元素的栈,一个元素放置在另一个元素上,这样一个组合有 \(n\) 个不同的符号标记。对于每个符号,栈中恰好有两个元素用一个符号标记。
玩家可以交换两个相邻元素,即互换他们的位置。交换后,如果有两个相邻的元素标有相同的符号,则将他们都从栈中删除。然后,位于其上方的所有元素都会掉落下来,并且可以造成再次删除。
玩家的目标是以最少的移动次数清空堆栈。请你编写一个程序,找出最少的移动次数及方案。
第一行一个整数 \(n\)。
接下来的 \(2n\) 行里给出了栈的初始内容,第 \(i+1\) 行包含一个整数 \(a_i\)($1 \leq a_i \leq n $),表示从底部数起第 \(i\) 个元素所标记的符号(每个符号都在栈中出现正好两次)。
最初不存在相邻的两个元素符号相同的情况,保证有不超过 \(10^6\) 次操作的方案。
第一行一个整数 \(m\) ,表示最小的移动次数。
接下来 \(m\) 行,每行输出一个数。
第 \(i + 1\) 行输出 \(p_i\),即表示玩家在第 \(i\) 步时选择交换 \(p_i\) 与 \(p_{i+1}\)。
如果存在多个方案,则输出其中任何一个。
相当于栈遇到一对立即执行,它会做出最大贡献。
因为消掉两个方块只会对其它方块的距离产生变化,用树状数组维护区间,调换方案循环输出即可。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
int a[N];
int tree[N];
int lowbit(int x) { return x & (-x); }
void update(int x, int k)
{
for (int i = x; i <= 2 * n; i += lowbit(i))
{
tree[i] += k;
}
}
int query(int x)
{
int res = 0;
for (int i = x; i > 0; i -= lowbit(i))
{
res += tree[i];
}
return res;
}
int b[N];
queue<int>q;
int main()
{
n = read();
for (int i = 1; i <= 2 * n; ++i)
{
a[i] = read();
}
int ans = 0;
for (int i = 1; i <= 2 * n; ++i)
{
if (!b[a[i]])
b[a[i]] = i;
else
{
int k=i - b[a[i]] - 1 + query(i) - query(b[a[i]] - 1);
ans+=k;
int l=b[a[i]]+query(b[a[i]]);
for(int i=l;i<=l+k-1;++i) q.push(i);
update(i, -1);
update(b[a[i]], -1);
}
}
printf("%d\n", ans);
while(!q.empty()){
printf("%d\n",q.front());
q.pop();
}
return 0;
}
线段树
- \(Segment~Tree\)
广受出题人和OIer们青睐的高级数据结构,更高效的区间操作,更巧妙的构造思想,携起手来,跨入OI新篇章。
Index 1:
\(n\) 个数,和在\(10^{18}\) 范围内。
也就是\(\sum~a_i~\leq~10^{18}\)
现在有「两种」操作
0 x y 把区间\([x,y]\) 内的每个数开方,下取整
1 x y询问区间\([x,y]\) 的每个数的和
有多组数据,数据以EOF结束,对于每组数据,输出数据的序号,每组数据之后输出一个空行。
不保证给出的区间\([x, y]\) 有\(x <= y\) ,如果\(x>y\) 请交换\(x\) ,\(y\) 。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int tree[N], a[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree[p] = tree[ls(p)] + tree[rs(p)];
}
void build(int p, int l, int r)
{
if (l == r)
{
tree[p] = a[l];
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void update(int nx, int ny, int l, int r, int p)
{
if (nx <= l && r <= ny)
{
if (r - l + 1 >= tree[p])
return;
}
if (l == r)
{
tree[p] = (int)sqrt(tree[p]);
return;
}
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p));
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p));
push_up(p);
}
int query(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return tree[p];
int mid = l + r >> 1;
if (nx <= mid)
res += query(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query(nx, ny, mid + 1, r, rs(p));
return res;
}
int n, m, cnt;
signed main()
{
while (scanf("%lld", &n) != EOF)
{
memset(tree, 0, sizeof(tree));
printf("Case #%lld:\n", ++cnt);
for (int i = 1; i <= n; ++i)
a[i] = read();
build(1, 1, n);
m = read();
while (m--)
{
char opt = getchar();
if (opt == '0')
{
int x = read(), y = read();
if (x > y)
swap(x, y);
update(x, y, 1, n, 1);
}
else
{
int x = read(), y = read();
if (x > y)
swap(x, y);
printf("%lld\n", query(x, y, 1, n, 1));
}
}
}
return 0;
}
Index 2:
有一个长度为 \(n(1≤n≤100000)\),初始值全为0的序列 \(a\) 。
给出 \(m(1≤m≤100000)\) 种操作或者询问:
1:将区间 \([x,y]\) 中的值全部加上 \(c\)
2:将区间 \([x,y]\) 中的值全部乘上 \(c\)
3:将区间 \([x,y]\) 中的值全部替换成 \(c\)
4:询问区间 \([x,y]\) 的 \(p\) 次方和 \((a_1^p+a_2^p+a_3^p+\dots+a_n^p)\), 其中 \(1\le p\le3\)
多组数据,以 0 0 结尾。
第一行 \(n\),\(m\) 有 \(n\) 个整数 \(m\) 个操作。
接下来 \(m\) 行,每行一个操作。
Aim 1:次方计算
建三棵线段树树,分别表示 \(p=1,2,3\)。
对于乘法,修改操作都十分容易,其中修改时需要把标记归位。
面对加法,需要运用到多项式的乘法。
注意运算顺序,先高次的。
\(sum3[p]=sum3[p]+3x\times sum2[p]+3x^2\times sum1[p]+(r-l+1)\times x^3\)
\(sum2[p]=sum2[p]+2x\times sum1[p]+(r-l+1)\times x^2\)
\(sum1[p]=sum1[p]+(r-l+1)\times x\)
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 10007;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int sum1[N], sum2[N], sum3[N], add[N], mul[N], alt[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
sum1[p] = (sum1[ls(p)] + sum1[rs(p)]) % Mod;
sum2[p] = (sum2[ls(p)] + sum2[rs(p)]) % Mod;
sum3[p] = (sum3[ls(p)] + sum3[rs(p)]) % Mod;
}
void build(int p, int l, int r)
{
add[p] = alt[p] = 0;
mul[p] = 1;
sum1[p] = sum2[p] = sum3[p] = 0;
if (l == r)
return;
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change_add(int p, int l, int r, int x)
{
x %= Mod;
sum3[p] = (((((sum3[p] % Mod + 3 * sum2[p] * x % Mod) % Mod) + 3 * sum1[p] % Mod * x % Mod * x % Mod)) + (r - l + 1) * x % Mod * x % Mod * x % Mod) % Mod;
sum2[p] = ((sum2[p] % Mod + 2 * x % Mod * sum1[p] % Mod) + (r - l + 1) * x % Mod * x % Mod) % Mod;
sum1[p] = (sum1[p] % Mod + (r - l + 1) * x % Mod) % Mod;
add[p] = (add[p] + x) % Mod;
}
void change_mul(int p, int l, int r, int x)
{
x %= Mod;
sum3[p] = (sum3[p] * x % Mod * x % Mod * x % Mod) % Mod;
sum2[p] = (sum2[p] * x % Mod * x % Mod) % Mod;
sum1[p] = (sum1[p] * x) % Mod;
add[p] = (add[p] * x) % Mod;
mul[p] = (mul[p] * x) % Mod;
}
void change_alt(int p, int l, int r, int x)
{
x %= Mod;
sum3[p] = (r - l + 1) * x % Mod * x % Mod * x % Mod;
sum2[p] = (r - l + 1) * x % Mod * x % Mod;
sum1[p] = (r - l + 1) * x % Mod;
mul[p] = 1;
add[p] = 0;
alt[p] = x;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
if (alt[p])
{
change_alt(ls(p), l, mid, alt[p]);
change_alt(rs(p), mid + 1, r, alt[p]);
alt[p] = 0;
}
if (mul[p] != 1)
{
change_mul(ls(p), l, mid, mul[p]);
change_mul(rs(p), mid + 1, r, mul[p]);
mul[p] = 1;
}
if (add[p])
{
change_add(ls(p), l, mid, add[p]);
change_add(rs(p), mid + 1, r, add[p]);
add[p] = 0;
}
}
void update_add(int nx, int ny, int l, int r, int p, int x)
{
if (nx <= l && r <= ny)
{
change_add(p, l, r, x);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_add(nx, ny, l, mid, ls(p), x);
if (ny > mid)
update_add(nx, ny, mid + 1, r, rs(p), x);
push_up(p);
}
void update_mul(int nx, int ny, int l, int r, int p, int x)
{
if (nx <= l && r <= ny)
{
change_mul(p, l, r, x);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_mul(nx, ny, l, mid, ls(p), x);
if (ny > mid)
update_mul(nx, ny, mid + 1, r, rs(p), x);
push_up(p);
}
void update_alt(int nx, int ny, int l, int r, int p, int x)
{
if (nx <= l && r <= ny)
{
change_alt(p, l, r, x);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_alt(nx, ny, l, mid, ls(p), x);
if (ny > mid)
update_alt(nx, ny, mid + 1, r, rs(p), x);
push_up(p);
}
int query(int nx, int ny, int l, int r, int p, int k)
{
int res = 0;
if (nx <= l && r <= ny)
{
if (k == 1)
return sum1[p];
if (k == 2)
return sum2[p];
if (k == 3)
return sum3[p];
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res = (res + query(nx, ny, l, mid, ls(p), k)) % Mod;
if (ny > mid)
res = (res + query(nx, ny, mid + 1, r, rs(p), k)) % Mod;
return res;
}
signed main()
{
while (scanf("%lld%lld", &n, &m))
{
if (n == 0 && m == 0)
break;
build(1, 1, n);
while (m--)
{
int opt = read(), x = read(), y = read(), c = read();
if (opt == 1)
{
update_add(x, y, 1, n, 1, c);
}
else if (opt == 2)
{
update_mul(x, y, 1, n, 1, c);
}
else if (opt == 3)
{
update_alt(x, y, 1, n, 1, c);
}
else
{
printf("%lld\n", query(x, y, 1, n, 1, c));
}
}
}
return 0;
}
Index 3:
现有 \(n\) 盏灯排成一排,从左到右依次编号为:\(1\),\(2\),……,\(n\)。然后依次执行 \(m\) 项操作。
操作分为两种:
- 指定一个区间 \([a,b]\),然后改变编号在这个区间内的灯的状态(把开着的灯关上,关着的灯打开);
- 指定一个区间 \([a,b]\),要求你输出这个区间内有多少盏灯是打开的。
灯在初始时都是关着的。
第一行有两个整数 \(n\) 和 \(m\),分别表示灯的数目和操作的数目。
接下来有 \(m\) 行,每行有三个整数,依次为:\(c\)、\(a\)、\(b\)。其中 \(c\) 表示操作的种类。
- 当 \(c\) 的值为 \(0\) 时,表示是第一种操作。
- 当 \(c\) 的值为 \(1\) 时,表示是第二种操作。
\(a\) 和 \(b\) 则分别表示了操作区间的左右边界。
对于 \(100\%\) 的测试点,保证 \(2\le n\le 10^5\),\(1\le m\le 10^5\),\(1\le a,b\le n\),\(c\in\{0,1\}\)。
Aim 1:维护取反
我们不难发现取反后的贡献会取反。
所以维护 \(1\) 的个数,修改时取反即可。
对于标记需要维护这段是否取反。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int tree[N], lazy[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree[p] = tree[ls(p)] + tree[rs(p)];
}
void build(int p, int l, int r)
{
lazy[p] = 0;
if (l == r)
{
tree[p] = 0;
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change(int p, int l, int r)
{
tree[p] = (r - l + 1) - tree[p];
lazy[p] ^= 1;
}
void push_down(int p, int l, int r)
{
if (!lazy[p])
return;
int mid = l + r >> 1;
change(ls(p), l, mid);
change(rs(p), mid + 1, r);
lazy[p] = 0;
}
void update(int nx, int ny, int l, int r, int p)
{
if (nx <= l && r <= ny)
{
tree[p] = (r - l + 1) - tree[p];
lazy[p] ^= 1;
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p));
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p));
push_up(p);
}
int query(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return tree[p];
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query(nx, ny, mid + 1, r, rs(p));
return res;
}
int n, m;
int main()
{
n = read(), m = read();
build(1, 1, n);
while (m--)
{
int opt = read(), l = read(), r = read();
if (opt == 0)
{
update(l, r, 1, n, 1);
}
else
{
printf("%d\n", query(l, r, 1, n, 1));
}
}
return 0;
}
Index 4:
维护一个数列 \(a_i\),支持两种操作:
-
1 l r K D:给出一个长度等于 \(r-l+1\) 的等差数列,首项为 \(K\),公差为 \(D\),并将它对应加到 \([l,r]\) 范围中的每一个数上。即:令 \(a_l=a_l+K,a_{l+1}=a_{l+1}+K+D\ldots a_r=a_r+K+(r-l) \times D\)。 -
2 p:询问序列的第 \(p\) 个数的值 \(a_p\)。
第一行两个整数数 \(n,m\) 表示数列长度和操作个数。
第二行 \(n\) 个整数,第 \(i\) 个数表示 \(a_i\)。
接下来的 \(m\) 行,每行先输入一个整数 \(opt\)。
若 \(opt=1\) 则再输入四个整数 \(l\ r\ K\ D\);
若 \(opt=2\) 则再输入一个整数 \(p\)。
对于 \(100\%\) 数据,\(0\le n,m \le 10^5,-200\le a_i,K,D\le 200, 1 \leq l \leq r \leq n, 1 \leq p \leq n\)。
如果您对前面的题毫无压力,那么这道题岂不是非常简单,切一道题目,放松一下!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 5e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N], b[N];
int tree[N], lazy[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree[p] = tree[ls(p)] + tree[rs(p)];
}
void build(int p, int l, int r)
{
lazy[p] = 0;
if (l == r)
{
tree[p] = b[l];
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change(int p, int l, int r, int add)
{
tree[p] += (r - l + 1) * add;
lazy[p] += add;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
change(ls(p), l, mid, lazy[p]);
change(rs(p), mid + 1, r, lazy[p]);
lazy[p] = 0;
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
change(p, l, r, k);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
{
return tree[p];
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query(nx, ny, mid + 1, r, rs(p));
return res;
}
signed main()
{
n = read(), m = read();
for (int i = 1; i <= n; ++i)
a[i] = read(), b[i] = a[i] - a[i - 1];
build(1, 1, n);
while (m--)
{
int opt = read();
if (opt == 1)
{
int l = read(), r = read(), k = read(), d = read();
update(l, l, 1, n, 1, k);
if (l + 1 <= r)
update(l + 1, r, 1, n, 1, d);
if (r + 1 <= n)
update(r + 1, r + 1, 1, n, 1, -(k + d * (r - l)));
}
else
{
int p = read();
printf("%lld\n", query(1, p, 1, n, 1));
}
}
return 0;
}
Index 5:
第一行包含两个正整数 \(N,M\),分别表示数列中实数的个数和操作的个数。
第二行包含 \(N\) 个实数,其中第 \(i\) 个实数表示数列的第 \(i\) 项。
接下来 \(M\) 行,每行为一条操作,格式为以下三种之一:
操作 \(1\):1 x y k ,表示将第 \(x\) 到第 \(y\) 项每项加上 \(k\),\(k\) 为一实数。
操作 \(2\):2 x y ,表示求出第 \(x\) 到第 \(y\) 项这一子数列的平均数。
操作 \(3\):3 x y ,表示求出第 \(x\) 到第 \(y\) 项这一子数列的方差。
关于方差:对于一个有 \(n\) 项的数列 \(A\),其方差 \(s^2\) 定义如下:
\]
其中 \(\overline A\) 表示数列 \(A\) 的平均数,\(A_i\) 表示数列 \(A\) 的第 \(i\) 项。
| 数据点 | \(N\) | \(M\) | 备注 |
|---|---|---|---|
| \(1\sim3\) | \(N\le 8\) | \(M\le 15\) | – |
| \(4\sim7\) | \(N\le 10^5\) | \(M\le 10^5\) | 不包含操作 \(3\) |
| \(8\sim10\) | \(N\le 10^5\) | \(M\le 10^5\) | – |
Aim 1:定新运算
您有可能是这样的。
方差也太复杂了,线段树做不了!
但是请不要。
现在我带您一起化简这个公式。
\]
\]
\]
\]
Aim 2:lazy标记
tree1 维护和 ; tree2 维护平方和
\]
\]
\]
\]
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
#define double long double
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
double tree1[N], tree2[N], lazy[N], a[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree1[p] = tree1[ls(p)] + tree1[rs(p)];
tree2[p] = tree2[ls(p)] + tree2[rs(p)];
}
void build(int p, int l, int r)
{
lazy[p] = 0;
if (l == r)
{
tree1[p] = a[l];
tree2[p] = a[l] * a[l];
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change(int p, int l, int r, double add)
{
tree2[p] += 2 * add * tree1[p] + (r - l + 1) * add * add;
tree1[p] += (r - l + 1) * add;
lazy[p] += add;
}
void push_down(int p, int l, int r)
{
if (!lazy[p])
return;
int mid = l + r >> 1;
change(ls(p), l, mid, lazy[p]);
change(rs(p), mid + 1, r, lazy[p]);
lazy[p] = 0;
}
void update(int nx, int ny, int l, int r, int p, double k)
{
if (nx <= l && r <= ny)
{
change(p, l, r, k);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
double query_add(int nx, int ny, int l, int r, int p)
{
double res = 0;
if (nx <= l && r <= ny)
return tree1[p];
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query_add(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query_add(nx, ny, mid + 1, r, rs(p));
return res;
}
double query_squ(int nx, int ny, int l, int r, int p)
{
double res = 0;
if (nx <= l && r <= ny)
return tree2[p];
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query_squ(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query_squ(nx, ny, mid + 1, r, rs(p));
return res;
}
int n, m;
signed main()
{
n = read(), m = read();
for (int i = 1; i <= n; ++i)
scanf("%Lf", &a[i]);
build(1, 1, n);
while (m--)
{
int opt = read(), l = read(), r = read();
if (opt == 1)
{
double k;
scanf("%Lf", &k);
update(l, r, 1, n, 1, k);
}
else if (opt == 2)
{
printf("%.4Lf\n", query_add(l, r, 1, n, 1) / (r - l + 1));
}
else
{
printf("%.4Lf\n", query_squ(l, r, 1, n, 1) / (r - l + 1) - (query_add(l, r, 1, n, 1) / (r - l + 1)) * (query_add(l, r, 1, n, 1) / (r - l + 1)));
}
}
return 0;
}
Index 6:
维护集合 \(S\) (\(S\) 初始为空)并最终输出 \(S\)。
五种运算如下:
U T:\(S = S \cup T\)I T:\(S = S \cap T\)D T:\(S = S – T\)C T:\(S = T – S\)S T:\(S = S \oplus T\)
集合的基本运算操作定义如下:
- \(A \cup B\):\(\{x | x \in A \vee x \in B\}\)
- \(A \cap B\):\(\{x | x \in A \wedge x \in B\}\)
- \(A – B\):\(\{x | x \in A \wedge x \notin B\}\)
- \(A \oplus B\):\((A-B)\cup (B-A)\)
输入 \(M\) 行。每行第一个字母描述操作类型,后面给出一个区间(区间用 (a,b),(a,b],[a,b),[a,b] 表示)。
输出一行若干区间,代表集合 \(S\),所有区间按递增顺序输出,相邻两个区间之间以一个空格隔开。
如果区间为空,输出 empty set。
$ 0 \leq a,b \leq 65535, M \leq 70000$
Aim 1:开闭区间
\([a,b]=[2a,2b]\)
\([a,b)=[2a,2b-1]\)
\((a,b]=[2a+1,2b]\)
\((a,b)=[2a+1,2b-1]\)
这样就方便了处理。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 131070 << 2;
const int M = 131070;
const int Mod = 1e9 + 7;
inline void read(int &rl, int &rr)
{
int x = 0, f = 1;
int f1 = 0, f2 = 0;
getchar();
char ch = getchar();
if (ch == '[')
f1 = 1;
ch = getchar();
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
if (f1)
rl = x * 2;
else
rl = x * 2 + 1;
ch = getchar();
x = 0;
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
if (ch == ']')
f2 = 1;
if (f2)
rr = x * 2;
else
rr = x * 2 - 1;
}
int alt[N], rev[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void build(int p, int l, int r)
{
alt[p] = -1;
rev[p] = 0;
if (l == r)
return;
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
}
void change_alt(int p, int l, int r, int k)
{
alt[p] = k;
rev[p] = 0;
}
void change_rev(int p, int l, int r, int k)
{
rev[p] ^= 1;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
if (alt[p] != -1)
{
change_alt(ls(p), l, mid, alt[p]);
change_alt(rs(p), mid + 1, r, alt[p]);
alt[p] = -1;
}
if (rev[p])
{
change_rev(ls(p), l, mid, rev[p]);
change_rev(rs(p), mid + 1, r, rev[p]);
rev[p] = 0;
}
}
void update_alt(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
alt[p] = k;
rev[p] = 0;
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_alt(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update_alt(nx, ny, mid + 1, r, rs(p), k);
}
void update_rev(int nx, int ny, int l, int r, int p)
{
if (nx <= l && r <= ny)
{
rev[p] ^= 1;
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_rev(nx, ny, l, mid, ls(p));
if (ny > mid)
update_rev(nx, ny, mid + 1, r, rs(p));
}
int ans[N];
void init(int p, int l, int r)
{
if (l == r)
{
ans[l] = (alt[p] == -1 ? 0 : alt[p]) ^ rev[p];
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
init(ls(p), l, mid);
init(rs(p), mid + 1, r);
}
int main()
{
build(1, 0, M);
char opt;
while (cin >> opt)
{
int l, r;
read(l, r);
if (l > r)
continue;
if (opt == 'U')
{
update_alt(l, r, 0, M, 1, 1);
}
else if (opt == 'I')
{
update_alt(1, l - 1, 0, M, 1, 0);
update_alt(r + 1, M, 0, M, 1, 0);
}
else if (opt == 'D')
{
update_alt(l, r, 0, M, 1, 0);
}
else if (opt == 'C')
{
update_alt(1, l - 1, 0, M, 1, 0);
update_rev(l, r, 0, M, 1);
update_alt(r + 1, M, 0, M, 1, 0);
}
else
{
update_rev(l, r, 0, M, 1);
}
}
init(1, 0, M);
int flag = 0;
int lft = -1;
for (int i = 0; i <= M; ++i)
{
if (ans[i])
{
if (lft == -1)
lft = i, flag = 1;
if (i == M || !ans[i + 1])
{
if (lft & 1)
printf("(%d,", (lft - 1) / 2);
else
printf("[%d,", lft / 2);
if (i & 1)
printf("%d) ", (i + 1) / 2);
else
printf("%d] ", i / 2);
lft = -1;
}
}
}
if (!flag)
printf("empty set\n");
return 0;
}
Index 7:
你有 \(n\) 个花瓶。
你会有 \(m\) 次操作。
1 A X 从 \(A\) 花瓶开始插 \(X\) 朵花,每插一朵往后找到空瓶子。插不玩就扔掉
2 A B 清理 \(A \sim B\) 的所有花。
Aim 1:树上二分
运用天然二分性确定插入的右端点,全面覆盖即可。
线段树的基本变形:二分
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int t;
int n, m;
int tree[N];
int alt[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p) { tree[p] = tree[ls(p)] + tree[rs(p)]; }
void build(int p, int l, int r)
{
alt[p] = -1;
tree[p] = 0;
if (l == r)
return;
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
}
void change_alt(int p, int l, int r, int k)
{
alt[p] = k;
tree[p] = (r - l + 1) * k;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
if (alt[p] != -1)
{
change_alt(ls(p), l, mid, alt[p]);
change_alt(rs(p), mid + 1, r, alt[p]);
alt[p] = -1;
}
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
alt[p] = k;
tree[p] = (r - l + 1) * k;
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return tree[p];
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query(nx, ny, mid + 1, r, rs(p));
return res;
}
int sol(int x, int cnt)
{
int l = x, r = n, res = 0;
while (l <= r)
{
int mid = l + r >> 1;
if (mid - x + 1 - query(x, mid, 1, n, 1) >= cnt)
{
res = mid;
r = mid - 1;
}
else
{
l = mid + 1;
}
}
return res;
}
signed main()
{
t = read();
while (t--)
{
n = read(), m = read();
build(1, 1, n);
while (m--)
{
int opt = read();
int A = read(), B = read();
if (opt == 1)
{
++A;
int num = n - A + 1 - query(A, n, 1, n, 1);
if (num == 0)
{
printf("Can not put any one.\n");
continue;
}
int l = sol(A, 1);
int r = sol(A, min(B, num));
update(l, r, 1, n, 1, 1);
if (l <= 0 || r <= 0 || l > r)
{
printf("Can not put any one.\n");
continue;
}
printf("%d %d\n", l - 1, r - 1);
}
else
{
++A, ++B;
printf("%lld\n", query(A, B, 1, n, 1));
update(A, B, 1, n, 1, 0);
}
}
printf("\n");
}
return 0;
}
Index 8:
有一面墙被分为 \(100000000\) 个小格子。
现在有 \(n\) 张海报覆盖在上面,上面的海报会遮住下面的海报,问最后能看到多少张海报。
第一行为整数 \(t\) 表示组数。
每组数据第一行 \(n\) 表示海报数。
接下来 \(n\) 行,每行两个整数 \(l,r\) 表示海报的左右端点。
对于 \(100\%\) 的数据,\(n\le 10000~1\le l,r \le 10000000\)
Aim 1:离散数据
我们发现海报数量远远小于方格数量。
便可以离散化节省空间,但需要注意的是如果两个数不相邻,也需要用不相邻的两个数作为它们离散化后的值。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int t, n;
struct node
{
int l, r;
} a[N];
int alt[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void build(int p, int l, int r)
{
alt[p] = -1;
if (l == r)
return;
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
}
void change(int p, int l, int r, int k)
{
alt[p] = k;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
if (alt[p] != -1)
{
change(ls(p), l, mid, alt[p]);
change(rs(p), mid + 1, r, alt[p]);
alt[p] = -1;
}
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
alt[p] = k;
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
}
bool vis[N];
int sol(int p, int l, int r)
{
if (alt[p] != -1)
{
if (vis[alt[p]])
return 0;
vis[alt[p]] = 1;
return 1;
}
if (l == r)
return 0;
push_down(p, l, r);
int mid = l + r >> 1;
return sol(ls(p), l, mid) + sol(rs(p), mid + 1, r);
}
vector<int> uni;
int main()
{
t = read();
while (t--)
{
uni.clear();
uni.push_back(-Mod);
memset(vis, 0, sizeof(vis));
n = read();
int cnt = 0;
for (int i = 1; i <= n; ++i)
a[i].l = read(), a[i].r = read(), uni.push_back(a[i].l), uni.push_back(a[i].r);
sort(uni.begin(), uni.end());
uni.erase(unique(uni.begin(), uni.end()), uni.end());
for (int i = 1; i <= n; ++i)
if (uni[i] - uni[i - 1] != 1)
uni.push_back(uni[i] - 1);
sort(uni.begin(), uni.end());
int m = uni.size() - 1;
build(1, 1, m);
for (int i = 1; i <= n; ++i)
{
update(lower_bound(uni.begin(), uni.end(), a[i].l) - uni.begin(), lower_bound(uni.begin(), uni.end(), a[i].r) - uni.begin(), 1, m, 1, i);
}
printf("%d\n", sol(1, 1, m));
}
return 0;
}
Index 9:
给一个序列
支持 3 种操作
0 u v t对于所有i \(u<=i<=v~~\) \(a[i]=\min(a[i],t)\)1 u v对于所有i \(u<=i<=v\) ,输出最大的 \(a[i]\)2 u v对于所有i \(u<=i<=v\) ,输出 \(a[i]\) 的和
Aim 1:极值修改
正常打标记,计算严格次大值。
然后正常的打标记
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e6 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int sum[N];
int ma[N], se[N], num[N], a[N], tag[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
sum[p] = sum[ls(p)] + sum[rs(p)];
ma[p] = max(ma[ls(p)], ma[rs(p)]);
if (ma[ls(p)] == ma[rs(p)])
{
se[p] = max(se[ls(p)], se[rs(p)]);
num[p] = num[ls(p)] + num[rs(p)];
}
else
{
se[p] = max(se[ls(p)], se[rs(p)]);
se[p] = max(se[p], min(ma[ls(p)], ma[rs(p)]));
num[p] = ma[ls(p)] > ma[rs(p)] ? num[ls(p)] : num[rs(p)];
}
}
void build(int p, int l, int r)
{
if (l == r)
{
tag[p] = 0;
sum[p] = a[l];
ma[p] = a[l];
se[p] = -1;
num[p] = 1;
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change(int p, int k)
{
if (k >= ma[p])
return;
sum[p] -= num[p] * (ma[p] - k);
ma[p] = k;
tag[p] = 1;
}
void push_down(int p)
{
change(ls(p), ma[p]);
change(rs(p), ma[p]);
tag[p] = 0;
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (k >= ma[p])
return;
if (nx <= l && r <= ny && k > se[p])
{
change(p, k);
return;
}
if (tag[p])
push_down(p);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query_sum(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return sum[p];
if (tag[p])
push_down(p);
int mid = l + r >> 1;
if (nx <= mid)
res += query_sum(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query_sum(nx, ny, mid + 1, r, rs(p));
return res;
}
int query_max(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return ma[p];
if (tag[p])
push_down(p);
int mid = l + r >> 1;
if (nx <= mid)
res = max(res, query_max(nx, ny, l, mid, ls(p)));
if (ny > mid)
res = max(res, query_max(nx, ny, mid + 1, r, rs(p)));
return res;
}
int t, n, m;
signed main()
{
t = read();
while (t--)
{
n = read(), m = read();
for (int i = 1; i <= n; ++i)
a[i] = read();
build(1, 1, n);
while (m--)
{
int opt = read(), l = read(), r = read(), k;
if (opt == 0)
{
k = read();
update(l, r, 1, n, 1, k);
}
else if (opt == 1)
{
printf("%d\n", query_max(l, r, 1, n, 1));
}
else
{
printf("%lld\n", query_sum(l, r, 1, n, 1));
}
}
}
return 0;
}
可持久化线段树
- \(Persistent~Segment~Tree\)
又名主席树,这里讲一个小故事。
这种算法是由HJT(真名暂不给出),正好是中国的一个主席的简称,于是因此得名。
另外一种说法,就是 可持久化(\(Persistent\)) 特别像 主席(\(President\))。估计是某个英语学得很好得人,说出的一个梗。
关于这种数据结构是基于线段树的一种新的数据结构,他的大致思想和动画比较相像,计算机为了使得存储的空间更小,只记录了每帧与前一帧的差距,经过类似“减法”的操作。
可持久化线段树正是参考了这样的处理方式,建了很多类似的线段树,为了时间上的优化与空间上的优化,它们会共用一个或多个儿子,这个看似“残缺”的线段树,却可以发挥“完整”的线段树一样的功能。
Index 1:
如题,给定 \(n\) 个整数构成的序列 \(a\),将对于指定的闭区间 \([l, r]\) 查询其区间内的第 \(k\) 小值。
第一行包含两个整数,分别表示序列的长度 \(n\) 和查询的个数 \(m\)。
第二行包含 \(n\) 个整数,第 \(i\) 个整数表示序列的第 \(i\) 个元素 \(a_i\)。
接下来 \(m\) 行每行包含三个整数 $ l, r, k$ , 表示查询区间 \([l, r]\) 内的第 \(k\) 小值。
- 对于 \(100\%\) 的数据,满足 \(1 \leq n,m \leq 2\times 10^5\),\(|a_i| \leq 10^9\),\(1 \leq l \leq r \leq n\),\(1 \leq k \leq r – l + 1\)。
Aim 1:离散数据
一定要离散化!
这里建的线段树都是值域线段树,但是需要注意的是,对于重复的数据一定要重复建,否则加减的时候会难以计算。
这里离散化的方法默认你应当会了。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 2e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int a[N], b[N], root[N];
struct Segment
{
int L, R, sum;
} tree[N << 5];
int cnt = 0;
int update(int l, int r, int pre, int x)
{
int rt = ++cnt;
tree[rt].L = tree[pre].L;
tree[rt].R = tree[pre].R;
tree[rt].sum = tree[pre].sum + 1;
if (l == r)
return rt;
int mid = l + r >> 1;
if (x <= mid)
tree[rt].L = update(l, mid, tree[pre].L, x);
else
tree[rt].R = update(mid + 1, r, tree[pre].R, x);
return rt;
}
int query(int nx, int ny, int l, int r, int k)
{
if (l == r)
return l;
int x = tree[tree[ny].L].sum - tree[tree[nx].L].sum;
int mid = l + r >> 1;
if (x >= k)
return query(tree[nx].L, tree[ny].L, l, mid, k);
else
return query(tree[nx].R, tree[ny].R, mid + 1, r, k - x);
}
int main()
{
n = read(), m = read();
for (int i = 1; i <= n; ++i)
a[i] = read(), b[i] = a[i];
sort(b + 1, b + n + 1);
int siz = unique(b + 1, b + n + 1) - b - 1;
for (int i = 1; i <= n; ++i)
{
int it = lower_bound(b + 1, b + siz + 1, a[i]) - b;
root[i] = update(1, siz, root[i - 1], it);
}
while (m--)
{
int l = read(), r = read(), k = read();
printf("%d\n", b[query(root[l - 1], root[r], 1, siz, k)]);
}
return 0;
}
Index 2:
求一个区间内小于等于 \(k\) 的个数。
和上题一样,只不过增加了二分查询。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int t, n, m;
int a[N], b[N], root[N];
struct Segment
{
int L, R, sum;
} tree[N * 40];
int cnt = 0;
int update(int l, int r, int pre, int x)
{
int rt = ++cnt;
tree[rt].L = tree[pre].L;
tree[rt].R = tree[pre].R;
tree[rt].sum = tree[pre].sum + 1;
if (l == r)
return rt;
int mid = l + r >> 1;
if (x <= mid)
tree[rt].L = update(l, mid, tree[pre].L, x);
else
tree[rt].R = update(mid + 1, r, tree[pre].R, x);
return rt;
}
int siz;
int query(int nx, int ny, int l, int r, int k)
{
if (l == r)
return l;
int mid = l + r >> 1;
int x = tree[tree[ny].L].sum - tree[tree[nx].L].sum;
if (x >= k)
return query(tree[nx].L, tree[ny].L, l, mid, k);
else
return query(tree[nx].R, tree[ny].R, mid + 1, r, k - x);
}
int solve(int x, int y, int k)
{
int l = x, r = y, res = 0;
while (l <= r)
{
int mid = l + r >> 1;
int tmp = b[query(root[x - 1], root[y], 1, siz, mid - x)];
if (tmp <= k)
{
l = mid + 1;
res = max(res, mid - x);
}
else
{
r = mid - 1;
}
}
if (b[query(root[x - 1], root[y], 1, siz, y - x + 1)] <= k)
{
return y - x + 1;
}
return res;
}
int main()
{
int Tcnt = 0;
t = read();
while (t--)
{
cnt = 0;
memset(root, 0, sizeof(root));
for (int i = 1; i <= 40 * n; ++i)
tree[i].L = tree[i].R = tree[i].sum = 0;
n = read(), m = read();
for (int i = 1; i <= n; ++i)
a[i] = read(), b[i] = a[i];
sort(b + 1, b + n + 1);
siz = unique(b + 1, b + n + 1) - b - 1;
for (int i = 1; i <= n; ++i)
{
int it = lower_bound(b + 1, b + siz + 1, a[i]) - b;
root[i] = update(1, siz, root[i - 1], it);
}
printf("Case %d:\n", ++Tcnt);
while (m--)
{
int l = read(), r = read(), k = read();
printf("%d\n", solve(l + 1, r + 1, k));
}
for (int i = 1; i <= 40 * n; ++i)
tree[i].L = tree[i].R = tree[i].sum = 0;
}
return 0;
}
树链剖分
- \(Heavy-light~Decomposition\)
树上的线段树!
Index 1:
一棵树上有 \(n\) 个节点,编号分别为 \(1\) 到 \(n\),每个节点都有一个权值 \(w\)。
我们将以下面的形式来要求你对这棵树完成一些操作:
I. CHANGE u t : 把结点 \(u\) 的权值改为 \(t\)。
II. QMAX u v: 询问从点 \(u\) 到点 \(v\) 的路径上的节点的最大权值。
III. QSUM u v: 询问从点 \(u\) 到点 \(v\) 的路径上的节点的权值和。
注意:从点 \(u\) 到点 \(v\) 的路径上的节点包括 \(u\) 和 \(v\) 本身。
输入文件的第一行为一个整数 \(n\),表示节点的个数。
接下来 \(n-1\) 行,每行 \(2\) 个整数 \(a\) 和 \(b\),表示节点 \(a\) 和节点 \(b\) 之间有一条边相连。
接下来一行 \(n\) 个整数,第 \(i\) 个整数 \(w_i\) 表示节点 \(i\) 的权值。
接下来 \(1\) 行,为一个整数 \(q\),表示操作的总数。
接下来 \(q\) 行,每行一个操作,以 CHANGE u t 或者 QMAX u v 或者 QSUM u v 的形式给出。
对于 \(100 \%\) 的数据,保证 \(1\le n \le 3\times 10^4\),\(0\le q\le 2\times 10^5\)。
中途操作中保证每个节点的权值 \(w\) 在 \(-3\times 10^4\) 到 \(3\times 10^4\) 之间。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
const int Inf = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int t, n;
int top[N], id[N], wt[N], dep[N], fa[N], son[N], siz[N], res;
struct edge
{
int to, next;
} e[N];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].next = head[u];
head[u] = cnt;
}
void dfs1(int u, int p)
{
dep[u] = dep[p] + 1;
fa[u] = p;
siz[u] = 1;
int maxn = -1;
for (int i = head[u]; i; i = e[i].next)
{
int v = e[i].to;
if (v == p)
continue;
dfs1(v, u);
siz[u] += siz[v];
if (siz[v] > maxn)
son[u] = v, maxn = siz[v];
}
}
int w[N];
void dfs2(int u, int topf)
{
top[u] = topf;
++res;
id[u] = res;
wt[res] = w[u];
if (!son[u])
return;
dfs2(son[u], topf);
for (int i = head[u]; i; i = e[i].next)
{
int v = e[i].to;
if (v == fa[u] || v == son[u])
continue;
dfs2(v, v);
}
}
int ans[N], tot[N], lazy[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
ans[p] = max(ans[ls(p)], ans[rs(p)]);
tot[p] = tot[ls(p)] + tot[rs(p)];
}
void build(int p, int l, int r)
{
lazy[p] = 0;
if (l == r)
{
ans[p] = wt[l];
tot[p] = wt[l];
return;
}
int mid = (l + r) >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
ans[p] = k;
tot[p] = k;
return;
}
int mid = (l + r) >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query_max(int nx, int ny, int l, int r, int p)
{
int res = -Inf;
if (nx <= l && r <= ny)
return ans[p];
int mid = (l + r) >> 1;
if (nx <= mid)
res = max(res, query_max(nx, ny, l, mid, ls(p)));
if (ny > mid)
res = max(res, query_max(nx, ny, mid + 1, r, rs(p)));
return res;
}
int query_add(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return tot[p];
int mid = (l + r) >> 1;
if (nx <= mid)
res = (res + query_add(nx, ny, l, mid, ls(p)));
if (ny > mid)
res = (res + query_add(nx, ny, mid + 1, r, rs(p)));
return res;
}
int query_range_max(int x, int y)
{
int res = -Inf;
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
res = max(res, query_max(id[top[x]], id[x], 1, n, 1));
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
res = max(res, query_max(id[x], id[y], 1, n, 1));
return res;
}
int query_range_add(int x, int y)
{
int res = 0;
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
res += query_add(id[top[x]], id[x], 1, n, 1);
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
res += query_add(id[x], id[y], 1, n, 1);
return res;
}
signed main()
{
n = read();
for (int i = 1; i < n; ++i)
{
int u = read(), v = read();
add_edge(u, v);
add_edge(v, u);
}
for (int i = 1; i <= n; ++i)
w[i] = read();
dfs1(1, 0);
dfs2(1, 1);
build(1, 1, n);
int q = read();
while (q--)
{
char s[10];
scanf("%s", s);
if (s[0] == 'C')
{
int x = read(), y = read();
update(id[x], id[x], 1, n, 1, y);
}
else if (s[0] == 'Q' && s[1] == 'M')
{
int x = read(), y = read();
printf("%lld\n", query_range_max(x, y));
}
else
{
int x = read(), y = read();
printf("%lld\n", query_range_add(x, y));
}
}
return 0;
}
Index 2:
爬啊爬,爬啊爬,毛毛虫爬到了一颗小小的“毛景树”下面,发现树上长着他最爱吃的毛毛果,“毛景树”上有 \(N\) 个节点和 \(N-1\) 条树枝,但节点上是没有毛毛果的,毛毛果都是长在树枝上的。但是这棵“毛景树”有着神奇的魔力,他能改变树枝上毛毛果的个数:
Change k w:将第k条树枝上毛毛果的个数改变为 \(w\) 个。Cover u v w:将节点 \(u\) 与节点 \(v\) 之间的树枝上毛毛果的个数都改变为 \(w\) 个。Add u v w:将节点 \(u\) 与节点 \(v\) 之间的树枝上毛毛果的个数都增加 \(w\) 个。
由于毛毛虫很贪,于是他会有如下询问:
Max u v:询问节点 \(u\) 与节点 \(v\) 之间树枝上毛毛果个数最多有多少个。
第一行一个正整数 \(N\)。
接下来 \(N-1\) 行,每行三个正整数 \(U_i,V_i\) 和 \(W_i\),第 \(i+1\) 行描述第 \(i\) 条树枝。表示第 \(i\) 条树枝连接节点 \(U_i\) 和节点 \(V_i\),树枝上有 \(W_i\) 个毛毛果。 接下来是操作和询问,以 Stop 结束。
对于毛毛虫的每个询问操作,输出一个答案。
对于全部数据,\(1\le N\le 10^5\),操作和询问数目不超过 \(10^5\)。
保证在任意时刻,所有树枝上毛毛果的个数都不会超过 \(10^9\) 个。
一遍不够,再来一遍,树剖的细节较多一定要多加练习。
Aim 1:边权转换
Q: 这不对啊!!!
A: 咋了?
Q: 你看树剖不是点权吗,这边权怎么弄?
A: 可以把边权挂在儿子上。
Q: 刑。
Q: 别走,不是查询咋搞?
A: 当你爬到一条链的时候我们吧祖先节点扣掉。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n;
int top[N], siz[N], son[N], w[N], id[N], dep[N], fa[N], res;
struct edge
{
int to, dis, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v, int w)
{
++cnt;
e[cnt].to = v;
e[cnt].dis = w;
e[cnt].nxt = head[u];
head[u] = cnt;
}
void dfs1(int u, int p)
{
siz[u] = 1;
dep[u] = dep[p] + 1;
fa[u] = p;
int maxn = -1;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p)
continue;
dfs1(v, u);
siz[u] += siz[v];
if (siz[v] > maxn)
{
maxn = siz[v], son[u] = v;
}
}
}
void dfs2(int u, int topf, int dist)
{
top[u] = topf;
++res;
id[u] = res;
int tmp = 0;
for (int i = head[u]; i; i = e[i].nxt)
if (e[i].to == son[u])
tmp = e[i].dis;
w[res] = dist;
if (!son[u])
return;
dfs2(son[u], topf, tmp);
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == fa[u] || v == son[u])
continue;
dfs2(v, v, e[i].dis);
}
}
int tree1[N], tree2[N];
int add[N], alt[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree1[p] = tree1[ls(p)] + tree1[rs(p)];
tree2[p] = max(tree2[ls(p)], tree2[rs(p)]);
}
void build(int p, int l, int r)
{
add[p] = 0;
alt[p] = -1;
if (l == r)
{
tree1[p] = tree2[p] = w[l];
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change_add(int p, int l, int r, int k)
{
tree1[p] += (r - l + 1) * k;
tree2[p] += k;
add[p] += k;
}
void change_alt(int p, int l, int r, int k)
{
tree1[p] = (r - l + 1) * k;
tree2[p] = k;
alt[p] = k;
add[p] = 0;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
if (alt[p] != -1)
{
change_alt(ls(p), l, mid, alt[p]);
change_alt(rs(p), mid + 1, r, alt[p]);
alt[p] = -1;
}
if (add[p])
{
change_add(ls(p), l, mid, add[p]);
change_add(rs(p), mid + 1, r, add[p]);
add[p] = 0;
}
}
void update_alt(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
change_alt(p, l, r, k);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_alt(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update_alt(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
void update_add(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
change_add(p, l, r, k);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update_add(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update_add(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query_max(int nx, int ny, int l, int r, int p)
{
int res = -Mod;
if (nx <= l && r <= ny)
return tree2[p];
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res = max(res, query_max(nx, ny, l, mid, ls(p)));
if (ny > mid)
res = max(res, query_max(nx, ny, mid + 1, r, rs(p)));
return res;
}
void update_range_alt(int x, int y, int k)
{
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
update_alt(id[top[x]], id[x], 1, n, 1, k);
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
update_alt(id[x] + 1, id[y], 1, n, 1, k);
}
void update_range_add(int x, int y, int k)
{
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
update_add(id[top[x]], id[x], 1, n, 1, k);
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
update_add(id[x] + 1, id[y], 1, n, 1, k);
}
int query_range_max(int x, int y)
{
int res = -Mod;
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
res = max(res, query_max(id[top[x]], id[x], 1, n, 1));
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
res = max(res, query_max(id[x] + 1, id[y], 1, n, 1));
return res;
}
struct node
{
int u, v, w;
} a[N];
int main()
{
n = read();
for (int i = 1; i < n; ++i)
{
int u = read(), v = read(), w = read();
add_edge(u, v, w);
add_edge(v, u, w);
a[i].u = u, a[i].v = v, a[i].w = w;
}
dfs1(1, 0);
dfs2(1, 1, 0);
build(1, 1, n);
string opt;
while (1)
{
cin >> opt;
if (opt == "Stop")
break;
int u, v, k;
if (opt == "Change")
{
u = read(), k = read();
update_range_alt(a[u].u, a[u].v, k);
}
else if (opt == "Cover")
{
u = read(), v = read(), k = read();
update_range_alt(u, v, k);
}
else if (opt == "Add")
{
u = read(), v = read(), k = read();
update_range_add(u, v, k);
}
else
{
u = read(), v = read();
printf("%d\n", query_range_max(u, v));
}
}
return 0;
}
Index 3:
Harry Potter 新学了一种魔法:可以让改变树上的果子个数。满心欢喜的他找到了一个巨大的果树,来试验他的新法术。
这棵果树共有 \(N\) 个节点,其中节点 \(0\) 是根节点,每个节点 \(u\) 的父亲记为 \(fa[u]\),保证有 \(fa[u] < u\) 。初始时,这棵果树上的果子都被 Dumbledore 用魔法清除掉了,所以这个果树的每个节点上都没有果子(即 \(0\) 个果子)。
不幸的是,Harry 的法术学得不到位,只能对树上一段路径的节点上的果子个数统一增加一定的数量。也就是说,Harry 的魔法可以这样描述:A u v d 。表示将点 \(u\) 和 \(v\) 之间的路径上的所有节点的果子个数都加上 \(d\)。
接下来,为了方便检验 Harry 的魔法是否成功,你需要告诉他在释放魔法的过程中的一些有关果树的信息:Q u。表示当前果树中,以点 \(u\) 为根的子树中,总共有多少个果子?
第一行一个正整数 \(N (1 \leq N \leq 100000)\),表示果树的节点总数,节点以 \(0,1,\dots,N – 1\) 标号,\(0\) 一定代表根节点。
接下来 \(N – 1\) 行,每行两个整数 \(a,b (0 \leq a < b < N)\),表示 \(a\) 是 \(b\) 的父亲。
接下来是一个正整数 \(Q(1 \leq Q \leq 100000)\),表示共有 \(Q\) 次操作。
后面跟着 \(Q\) 行,每行是以下两种中的一种:
-
A u v d,表示将 \(u\) 到 \(v\) 的路径上的所有节点的果子数加上 \(d\)。保证 \(0 \leq u,v < N,0 < d < 100000\) -
Q u,表示询问以 \(u\) 为根的子树中的总果子数,注意是包括 \(u\) 本身的。
对于所有的 Q 操作,依次输出询问的答案,每行一个。答案可能会超过 \(2^{32}\) ,但不会超过 \(10^{15}\) 。
经过上面地训练,为了增强码力要有一定地练习量。
限时:30min(编码+调试)
要求:一遍通过
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
#define int long long
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
struct node
{
int to, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
int top[N], id[N], fa[N], son[N], siz[N], dep[N], res;
void dfs1(int u, int p)
{
dep[u] = dep[p] + 1;
siz[u] = 1;
fa[u] = p;
int maxn = -1;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p)
continue;
dfs1(v, u);
siz[u] += siz[v];
if (siz[v] > maxn)
maxn = siz[v], son[u] = v;
}
}
void dfs2(int u, int topf)
{
top[u] = topf;
id[u] = ++res;
if (!son[u])
return;
dfs2(son[u], topf);
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == fa[u] || v == son[u])
continue;
dfs2(v, v);
}
}
int n, m;
int tree[N], lazy[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree[p] = tree[ls(p)] + tree[rs(p)];
}
void change(int p, int l, int r, int k)
{
lazy[p] += k;
tree[p] += (r - l + 1) * k;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
change(ls(p), l, mid, lazy[p]);
change(rs(p), mid + 1, r, lazy[p]);
lazy[p] = 0;
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
change(p, l, r, k);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return tree[p];
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query(nx, ny, mid + 1, r, rs(p));
return res;
}
void update_range(int x, int y, int k)
{
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
update(id[top[x]], id[x], 1, n, 1, k);
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
update(id[x], id[y], 1, n, 1, k);
}
int query_tree(int x)
{
return query(id[x], id[x] + siz[x] - 1, 1, n, 1);
}
signed main()
{
n = read();
for (int i = 1; i < n; ++i)
{
int u = read() + 1, v = read() + 1;
add_edge(u, v);
add_edge(v, u);
}
dfs1(1, 0);
dfs2(1, 1);
m = read();
while (m--)
{
getchar();
char opt = getchar();
int u, v, d;
if (opt == 'A')
{
u = read() + 1, v = read() + 1, d = read();
update_range(u, v, d);
}
else
{
u = read() + 1;
printf("%lld\n", query_tree(u));
}
}
return 0;
}
Index 4:
给定一棵 \(n\) 个节点的无根树,共有 \(m\) 个操作,操作分为两种:
- 将节点 \(a\) 到节点 \(b\) 的路径上的所有点(包括 \(a\) 和 \(b\))都染成颜色 \(c\)。
- 询问节点 \(a\) 到节点 \(b\) 的路径上的颜色段数量。
颜色段的定义是极长的连续相同颜色被认为是一段。例如 112221 由三段组成:11、222、1。
输入的第一行是用空格隔开的两个整数,分别代表树的节点个数 \(n\) 和操作个数 \(m\)。
第二行有 \(n\) 个用空格隔开的整数,第 \(i\) 个整数 \(w_i\) 代表结点 \(i\) 的初始颜色。
第 \(3\) 到第 \((n + 1)\) 行,每行两个用空格隔开的整数 \(u, v\),代表树上存在一条连结节点 \(u\) 和节点 \(v\) 的边。
第 \((n + 2)\) 到第 \((n + m + 1)\) 行,每行描述一个操作,其格式为:
每行首先有一个字符 \(op\),代表本次操作的类型。
- 若 \(op\) 为
C,则代表本次操作是一次染色操作,在一个空格后有三个用空格隔开的整数 \(a, b, c\),代表将 \(a\) 到 \(b\) 的路径上所有点都染成颜色 \(c\)。 - 若 \(op\) 为
Q,则代表本次操作是一次查询操作,在一个空格后有两个用空格隔开的整数 \(a, b\),表示查询 \(a\) 到 \(b\) 路径上的颜色段数量。
对于每次查询操作,输出一行一个整数代表答案。
对于 \(100\%\) 的数据,\(1 \leq n, m \leq 10^5\),\(1 \leq w_i, c \leq 10^9\),\(1 \leq a, b, u, v \leq n\),\(op\) 一定为 C 或 Q,保证给出的图是一棵树。
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 4e5 + 50;
const int M = 1e5 + 50;
const int Mod = 1e9 + 7;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, m;
int w[N], wt[N], id[N], top[N], dep[N], fa[N], son[N], siz[N], res;
struct edge
{
int to, nxt;
} e[N];
int head[N], cnt;
void add_edge(int u, int v)
{
++cnt;
e[cnt].to = v;
e[cnt].nxt = head[u];
head[u] = cnt;
}
void dfs1(int u, int p)
{
fa[u] = p;
dep[u] = dep[p] + 1;
siz[u] = 1;
int maxn = -1;
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == p)
continue;
dfs1(v, u);
siz[u] += siz[v];
if (siz[v] > maxn)
son[u] = v, maxn = siz[v];
}
}
void dfs2(int u, int topf)
{
top[u] = topf;
++res;
id[u] = res;
wt[res] = w[u];
if (!son[u])
return;
dfs2(son[u], topf);
for (int i = head[u]; i; i = e[i].nxt)
{
int v = e[i].to;
if (v == fa[u] || v == son[u])
continue;
dfs2(v, v);
}
}
struct node
{
int l, r, num, lc, rc, alt;
} tree[N];
int ls(int p) { return p << 1; }
int rs(int p) { return p << 1 | 1; }
void push_up(int p)
{
tree[p].num = tree[ls(p)].num + tree[rs(p)].num;
tree[p].lc = tree[ls(p)].lc, tree[p].rc = tree[rs(p)].rc;
if (tree[ls(p)].rc == tree[rs(p)].lc)
tree[p].num--;
}
void build(int p, int l, int r)
{
tree[p].l = l, tree[p].r = r;
tree[p].alt = -1;
if (l == r)
{
tree[p].lc = tree[p].rc = wt[l];
tree[p].num = 1;
return;
}
int mid = l + r >> 1;
build(ls(p), l, mid);
build(rs(p), mid + 1, r);
push_up(p);
}
void change(int p, int l, int r, int k)
{
tree[p].num = 1;
tree[p].lc = tree[p].rc = k;
tree[p].alt = k;
}
void push_down(int p, int l, int r)
{
int mid = l + r >> 1;
if (tree[p].alt != -1)
{
change(ls(p), l, mid, tree[p].alt);
change(rs(p), mid + 1, r, tree[p].alt);
tree[p].alt = -1;
}
}
void update(int nx, int ny, int l, int r, int p, int k)
{
if (nx <= l && r <= ny)
{
change(p, l, r, k);
return;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
update(nx, ny, l, mid, ls(p), k);
if (ny > mid)
update(nx, ny, mid + 1, r, rs(p), k);
push_up(p);
}
int query(int nx, int ny, int l, int r, int p)
{
int res = 0;
if (nx <= l && r <= ny)
return tree[p].num;
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
res += query(nx, ny, l, mid, ls(p));
if (ny > mid)
res += query(nx, ny, mid + 1, r, rs(p));
if (nx <= mid && ny > mid)
{
if (tree[ls(p)].rc == tree[rs(p)].lc)
res--;
}
return res;
}
void update_range(int x, int y, int k)
{
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
update(id[top[x]], id[x], 1, n, 1, k);
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
update(id[x], id[y], 1, n, 1, k);
}
int query_col(int nx, int ny, int l, int r, int p)
{
if (nx <= l && r <= ny)
{
return tree[p].lc;
}
push_down(p, l, r);
int mid = l + r >> 1;
if (nx <= mid)
return query_col(nx, ny, l, mid, ls(p));
if (ny > mid)
return query_col(nx, ny, mid + 1, r, rs(p));
}
int query_range(int x, int y)
{
int res = 0;
while (top[x] != top[y])
{
if (dep[top[x]] < dep[top[y]])
swap(x, y);
res += query(id[top[x]], id[x], 1, n, 1);
int lc = query_col(id[top[x]], id[top[x]], 1, n, 1);
int rc = query_col(id[fa[top[x]]], id[fa[top[x]]], 1, n, 1);
if (lc == rc)
res--;
x = fa[top[x]];
}
if (dep[x] > dep[y])
swap(x, y);
res += query(id[x], id[y], 1, n, 1);
return res;
}
int main()
{
n = read(), m = read();
for (int i = 1; i <= n; ++i)
w[i] = read();
for (int i = 1; i < n; ++i)
{
int u = read(), v = read();
add_edge(u, v);
add_edge(v, u);
}
dfs1(1, 0);
dfs2(1, 1);
build(1, 1, n);
while (m--)
{
char opt;
cin >> opt;
if (opt == 'C')
{
int x = read(), y = read(), k = read();
update_range(x, y, k);
}
else
{
int x = read(), y = read();
printf("%d\n", query_range(x, y));
}
}
return 0;
}
矩阵
- \(Matrix\)
现代信息的前沿,速度决定一切!
Index 1:
该有向图有 \(n\) 个节点,节点从 \(1\) 至 \(n\) 编号,windy 从节点 \(1\) 出发,他必须恰好在 \(t\) 时刻到达节点 \(n\)。
现在给出该有向图,你能告诉 windy 总共有多少种不同的路径吗?
注意:windy 不能在某个节点逗留,且通过某有向边的时间严格为给定的时间。
第一行包含两个整数,分别代表 \(n\) 和 \(t\)。
第 \(2\) 到第 \((n + 1)\) 行,每行一个长度为 \(n\) 的字符串,第 \((i + 1)\) 行的第 \(j\) 个字符 \(c_{i, j}\) 是一个数字字符,若为 \(0\),则代表节点 \(i\) 到节点 \(j\) 无边,否则代表节点 \(i\) 到节点 \(j\) 的边的长度为 \(c_{i, j}\)。
输出一行一个整数代表答案对 \(2009\) 取模的结果。
对于 \(100\%\) 的数据,保证 \(2 \leq n \leq 10\),\(1 \leq t \leq 10^9\)。
Aim 1:邻接矩阵
下面为一个图的邻接矩阵。

平方后。

立方后。

我们发现 \(a[i][j]\) 就是方案数。
Aim 2:一分为九
上面的例子是边权为1。
那么如何转换呢,运用拆点的思想,且十分符合此题的数据。
将一个点拆成九个点,这不就转换成功了吗!
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
typedef double db;
const int N = 1e5 + 50;
const int M = 1e5 + 50;
const int Mod = 2009;
inline int read()
{
int x = 0, f = 1;
char ch = getchar();
while (ch < '0' || ch > '9')
{
if (ch == '-')
f = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9')
{
x = (x << 1) + (x << 3) + (ch ^ 48);
ch = getchar();
}
return x * f;
}
int n, nn, t;
struct Martix
{
int a[110][110];
Martix() { memset(a, 0, sizeof(a)); }
Martix operator*(const Martix &b) const
{
Martix res;
for (int i = 1; i <= nn; ++i)
{
for (int j = 1; j <= nn; ++j)
{
for (int k = 1; k <= nn; ++k)
{
res.a[i][j] = (res.a[i][j] + a[i][k] * b.a[k][j]) % Mod;
}
}
}
return res;
}
} A, B;
void qbow(int k)
{
for (int i = 1; i <= nn; ++i)
B.a[i][i] = 1;
while (k)
{
if (k & 1)
B = B * A;
A = A * A;
k >>= 1;
}
}
signed main()
{
n = read(), t = read();
nn = n * 10;
for (int i = 1; i <= n; ++i)
for (int j = 1; j < 9; ++j)
A.a[10 * (i - 1) + j][10 * (i - 1) + j + 1] = 1;
for (int i = 1; i <= n; ++i)
{
for (int j = 1; j <= n; ++j)
{
int opt;
scanf("%1d", &opt);
A.a[10 * (i - 1) + opt][10 * (j - 1) + 1] = 1;
}
}
qbow(t);
printf("%d\n", B.a[1][n * 10 - 9]);
return 0;
}